Multi-Task Learning(MTL)即多任务学习,在一些领域也被称为多目标学习。MTL与常规单任务模型的区别在于,MTL仅使用一个模型就可以处理多个任务。比如对于手机唤醒这个场景,一般需要两个模型,一个模型来检测是否是手机用户的语音,避免环境音和自身回音干扰,另外一个模型用于检测用户语音是否有唤醒词(如:Hey Siri、小爱同学等)。借助MTL,则可以在一个模型中同时完成上述两个任务。再比如,阿里巴巴针对电商领域提出的ESMM模型,对CTR和CVR两个任务同时建模,解决了训练空间和预测空间不一致的问题,并同时利用点击数据和转化数据进行全局优化。
MTL(Multi-Task Learning)
STL、MTL和其他学习
单任务模型,即每个任务,输入一致,但是独立训练和预测;
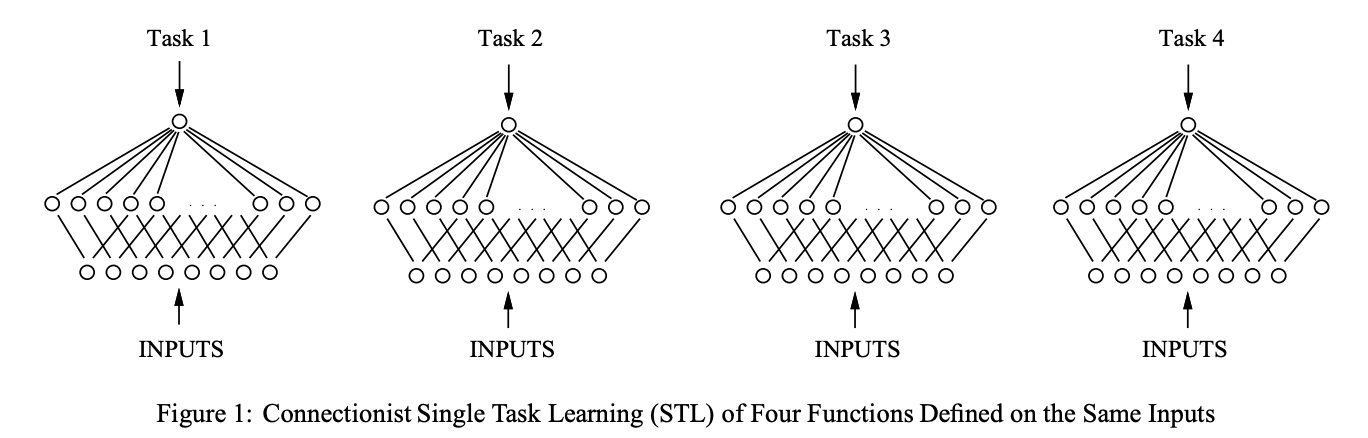
多任务模型中,神经网络有多个输出的节点,每个节点对应一个任务,最简单的MTL模型如下:
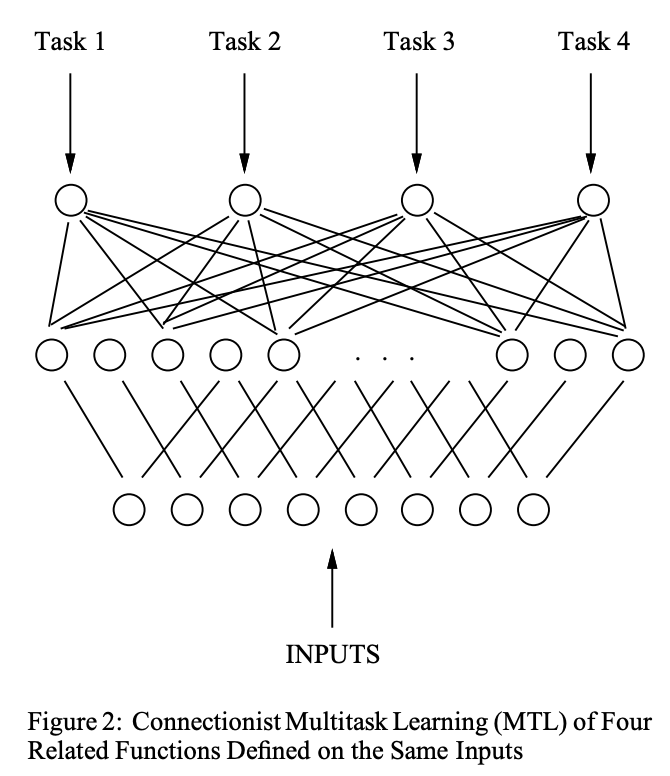
使用MTL而非单任务模型的三个实用理由如下:
- MTL可以在模型效果不下降的情况下提升多任务预测效率。由于共享部分网络,MTL总网络参数少于N个单任务网络参数,对实时任务预测场景效率更高;同时,对某个任务而言,MTL模型参数(共享参数+任务独立参数)与单任务参数数量一样,所以理论上来说,模型表达能力并没有降低。
- MTL对于相关性强的多任务,可以提升小样本任务训练效果。这主要得益于MTL的参数共享机制,共享参数可以通过样本充足的任务得到充分训练,减少小样本任务单独训练不充分,容易过拟合的问题。比如,ESMM模型,电商领域的转化数据(正样本)非常稀疏,CVR网络的嵌入层与CTR网络的嵌入层共享,类似于迁移学习的思想,使得其能够从未点击的曝光数据学习更新。
- MTL通过引入归纳偏置(Inductive Bias),可以提升所有相关任务的鲁棒性。在机器学习中,无时无刻都在对问题做一些假设(或者叫先验、约束),这些就被称为归纳偏置,如 L1正则是模型稀疏性的假设、CNN 是特征局部性的假设、RNN是样本时序性的假设……对于MTL,归纳偏置则是不同任务之间效果的约束,如果这些约束合理,那么显然会让所有任务都更不容易受噪声样本影响,从而提升模型的鲁棒性。
上面的几点优势本质上都是“共享参数带来的。因此,如果不同任务之间的差异巨大,根本没必要共享,这种情况下,“共享参数”机制就会使归纳偏置从约束变成噪声,拉低每一个任务的效果,这种现象也称为负迁移。除了负迁移还有,多任务学习中常常会出现某些任务性能提高而某些任务性能下降的现象,即跷跷板现象(seesaw phenomenon)。后续的MMoE和PLE是针对多任务关联性较弱时出现的负迁移现象。
下图是多任务学习与其他学习的关系:
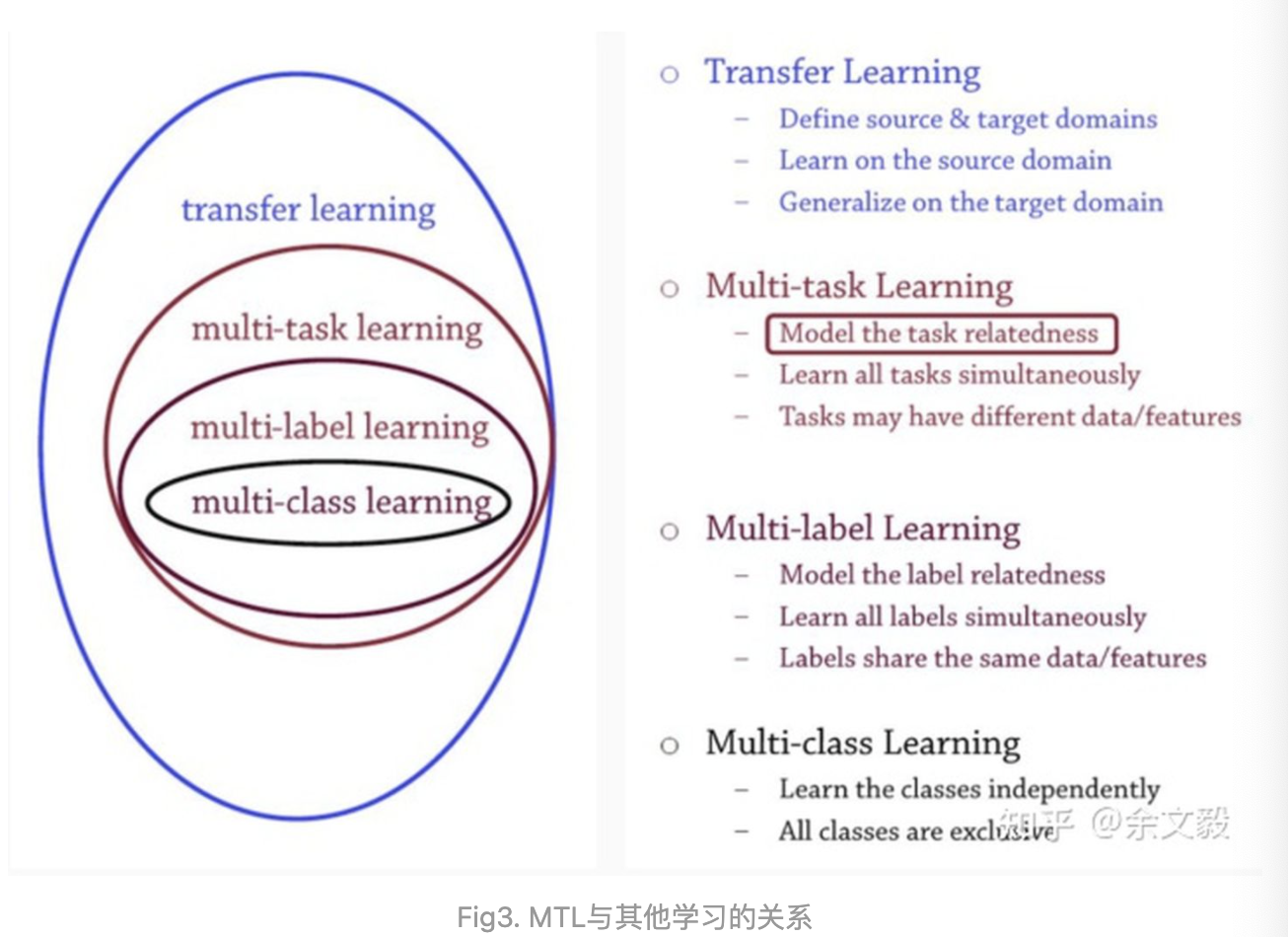
Multi-Task Learning的形式
对于任务的定义,包括如下:
- 源数据:$X$表示某领域的样本集合;
- 目标数据:$Y$表示某领域的目标集合;
- 映射:$f:X \rightarrow Y$,表示从源到目标的转换关系。
对于一个MTL模型,能够同时对多个上述任务进行建模。模型中部分参数是所有任务共享的,下面称为“共享参数”;另外一部分参数是每个任务独享的,下面称为“独立参数”。那么理想情况下,我们希望“共享参数”在所有样本计算Loss后更新,而“独立参数”只在对应任务样本计算Loss后才更新,这就达到了一起训练的目的。
根据上述定义,MTL有以下三种形式:
- SIMO(Single Input Multi Output):给定一个源数据集$X$,以及多个目标数据集$(Y_1,Y_2,\cdots,Y_n)$,MTL将$X$分别映射到每个目标数据集中,下图(a),该形式最普遍。
- MIMO(Multi Input Multi Output):给定多个源数据集$(X_1,X_2,\cdots,X_n)$,以及多个目标数据集$(Y_1,Y_2,\cdots,Y_n)$,MTL分别将$X_i$映射到$Y_i$,如图4(c)。这种形式不如第一种常见,却是大部分场景下,最容易将单任务快速迁移到MTL进行尝试的方式。
- MISO(Multi Input Single Output):给定多个源数据集$(X_1,X_2,\cdots,X_n)$,以及一个目标数据集$Y$,MTL分别将$X_i$映射到目标$Y$,如图4(b)。如果这里$Y$被定义为所有源数据集的目标的超集,这个MTL任务就退化成上面提到的Multi-Label Learning任务。这种形式一般不被当成是MTL。
MTL的形式指的是如何组合不同任务的数据,而不是仅仅指网络结构。举个例子,对于Multi Input Multi Output形式的MTL模型,每个任务的源数据集不同,但如果Multi Input的特征完全一致,大可以共享特征解析部分的网络参数。
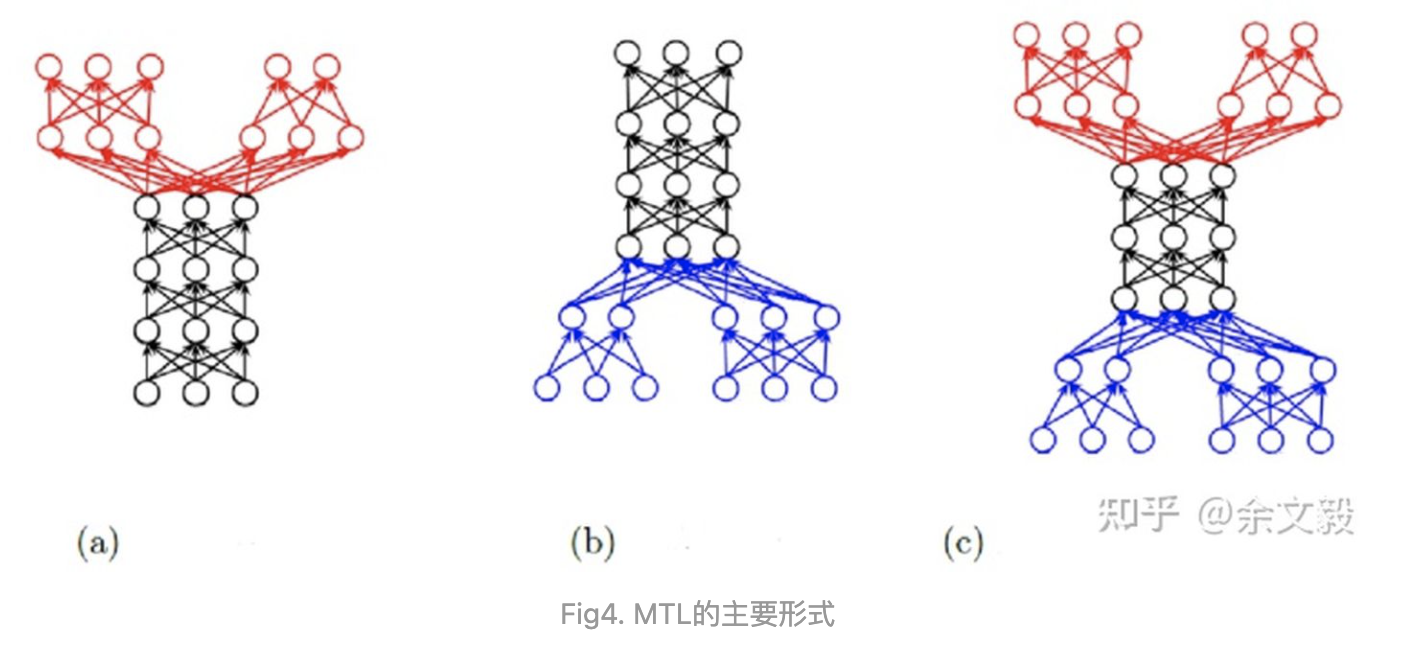
多任务学习参数共享形式
Hard/Soft 参数共享
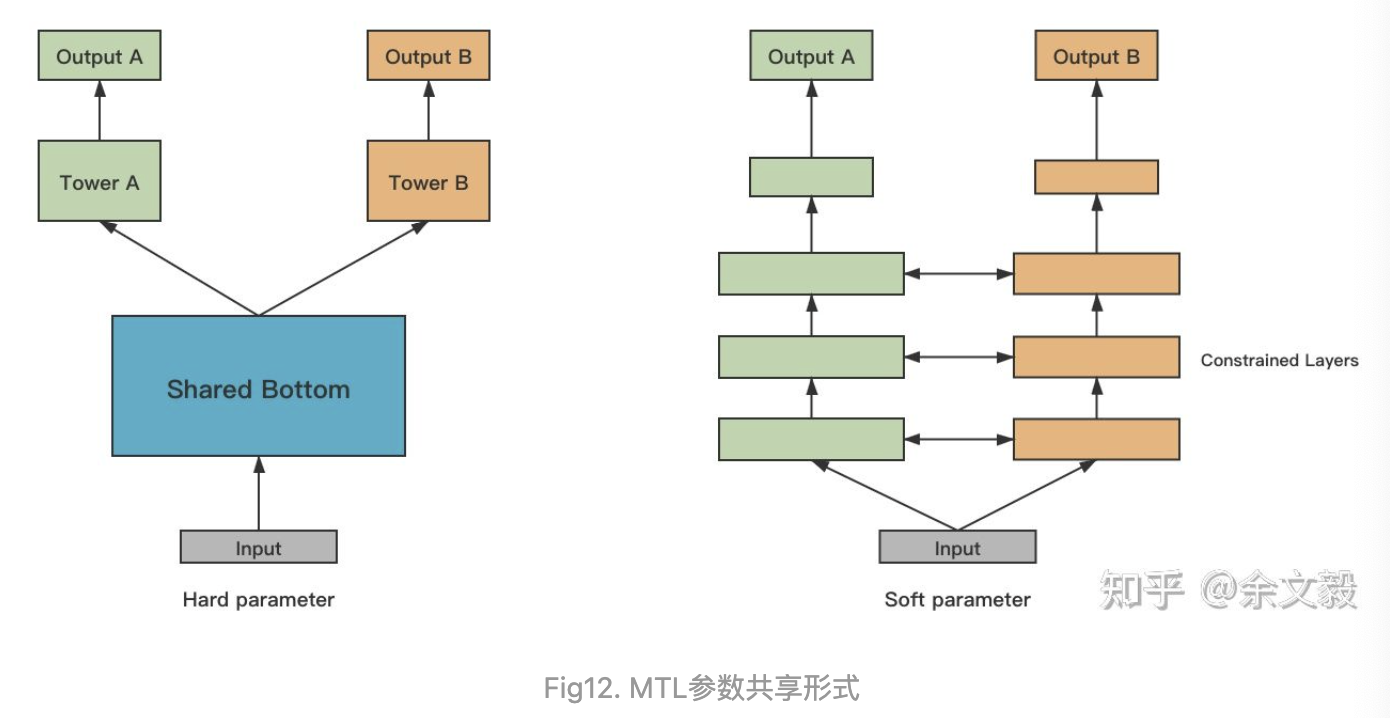
MTL模型中参数共享的方式一般说来有两种,分别是Hard Parameter Sharing和Soft Parameter Sharing。
Hard Parameter Sharing即上图左,表示对多任务直接共享部分神经网络参数,是最主流的参数共享形式,适用于多任务之间相关性比较强的场景。
Soft Parameter Sharing即上图右,表示每个任务分别有自己的神经网络参数,但是会对多任务的网络参数之间加约束,使参数彼此相似。这种方式实际中不太常见,可用于多任务之间相关性比较弱的场景。约束指标如L2 Norm和Trace Norm等。
Mixture os Experts
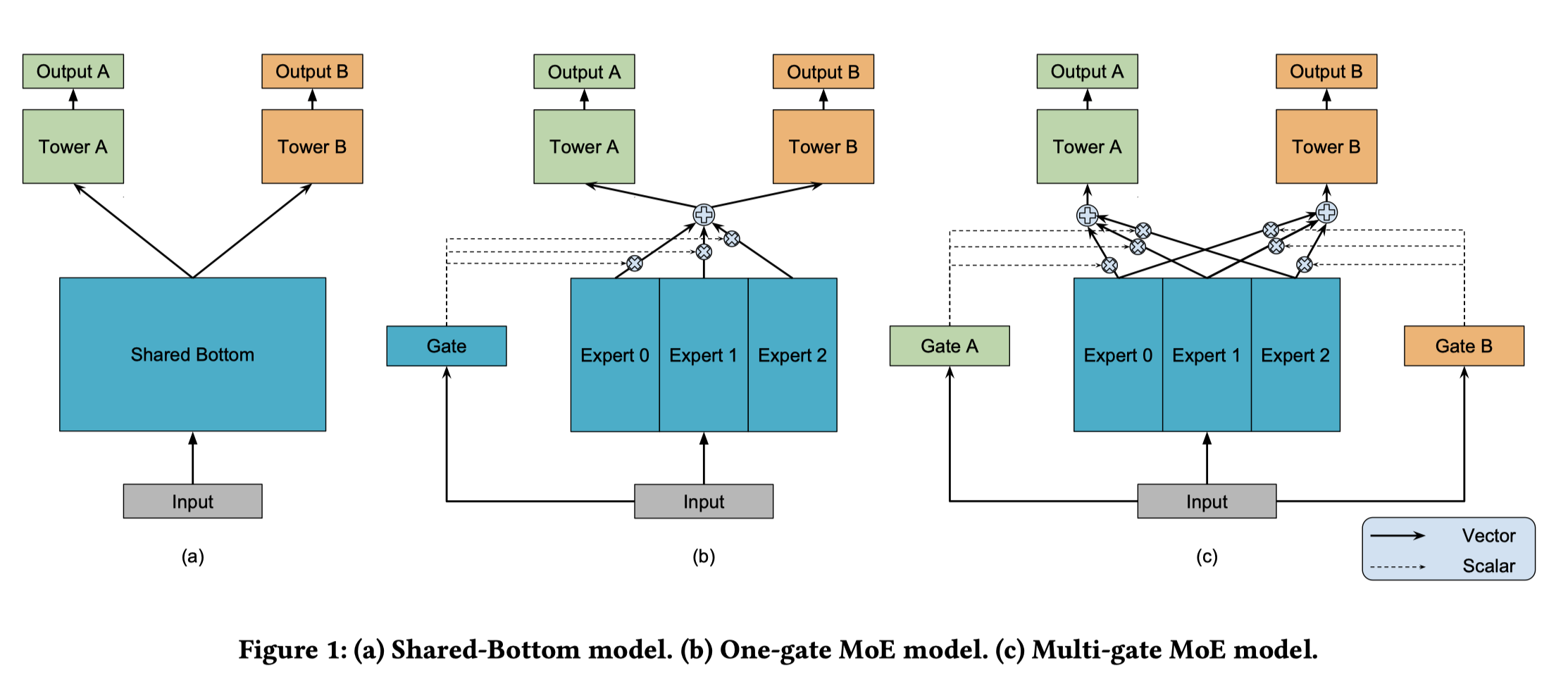
上面提到Soft Parameter Sharing可用于多任务之间相关性较较弱的场景,但是如果多任务之间相关性非常低,一般也不会考虑使用MTL。更常见的是,多任务之前有较为相关的部分,也有相互独立的部分,直接Hard Parameter Sharing也不太合适,Mixture of Experts模型就适合这种场景。
Google在2018年提出的MMoE模型,是对Geoffrey Hinton 提出的MoE和OMoE的一种改进,而它们都是一种特殊的Hard Parameter Sharing模型,这三种模型结构如上图。
Hard Parameter Sharing即Shared-Bottom model,对于$K$个任务,共享网络表示为$f$,$k$个tower网络表示为$h_k$,其中$k=1,2,\cdots,K$,代表每个任务,对于任务$k$,模型可被形式化地表示为:
MoE模型将“共享参数”划分为$N$个Expert子网络,而Gate网络负责输出$N$个Expert子网络的权重,最终结果是Expert子网络与Gate的加权和,思想上其实类似于后来的Attenton,可被形式化地表示为:
$g(x)_i$表示第$i$个$g(x)$的逻辑输出,即$f_i$的概率。$f_i,i=1,2,c\dots,n$是$n$个专家网络,$g$组合所有专家结果的门控网络。 更具体地说,门控网络$g$根据输入生成$n$个专家的分布,最终输出是所有专家的输出的加权总和。显然,MoE可看做基于多个独立模型的集成方法。这里注意MoE并不对应上图中的b部分。还有一些后续文章将MoE作为一个基本的组成单元,将多个MoE结构堆叠在一个大网络中,比如一个MoE层可以接受上一层MoE层的输出作为输入,其输出作为下一层的输入使用。
MMoE则是在MoE的基础上,对每一个任务有独自的Gate网络负责输出权重,使不同的任务能更多样化地使用Expert网络。
2018 KDD MMoE
Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Expert 使用多门专家混合在多任务学习中建模任务关系
MMoE基于广泛使用的Shared-Bottom结构和MoE结构,对每一个任务有独自的Gate网络负责输出权重,使不同的任务能更多样化地使用Expert网络。这样可以便可以刻画任务的相关性(Shared-Bottom),并基于共享表示来学习模特定任务的函数(每个特定任务有自己的Gate网络,而非MoE中所有任务公用一个Gate网络),相比于MoE,降低了了相关性低的任务间的噪声带来的影响,避免了明显增加参数的缺点。
即上部分Mixture os Experts的图(c),形式化地表示为:
可以看出,门网络处理共享的子网络(或者称为专家)的输出,具体实现相当于一个softmax全连接层,输入是输入特征,输出是所有专家(共享子网络)上的权重。
一方面,因为gating networks通常是轻量级的,而且expert networks是所有任务共用,所以相对于论文中提到的一些baseline方法在计算量和参数量上具有优势。
另一方面,相对于所有任务公共一个门控网络(One-gate MoE model,如图(b),这里MMoE(图(c))中每个任务使用单独的门网络。每个任务的门网络通过最终输出权重不同实现对专家的选择性利用。不同任务的门网络可以学习到不同的组合专家的模式,因此模型考虑到了捕捉到任务的相关性和区别。
2020 RecSys PLE
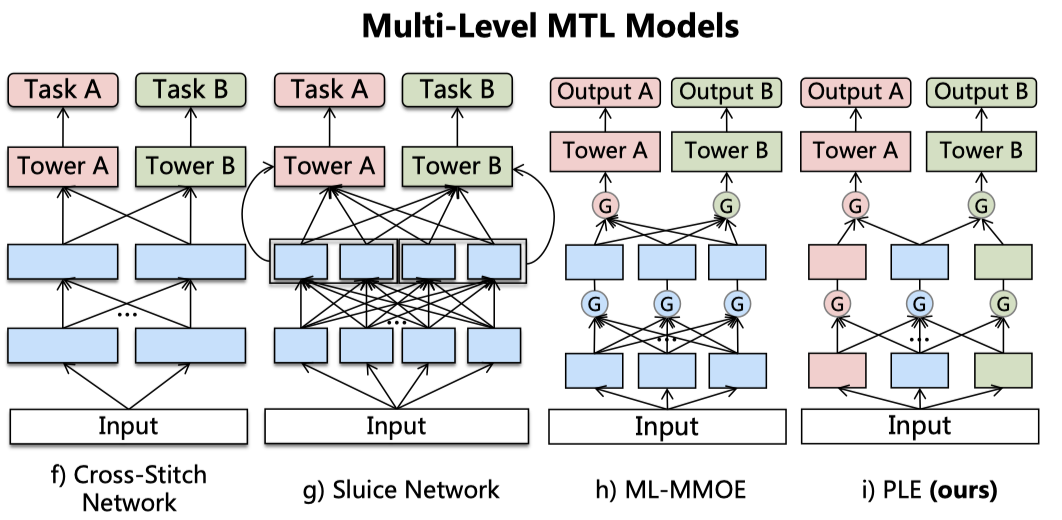
文章针对多任务学习中低关联性任务中存在的负迁移现象,提出了CGC结构,如下图:
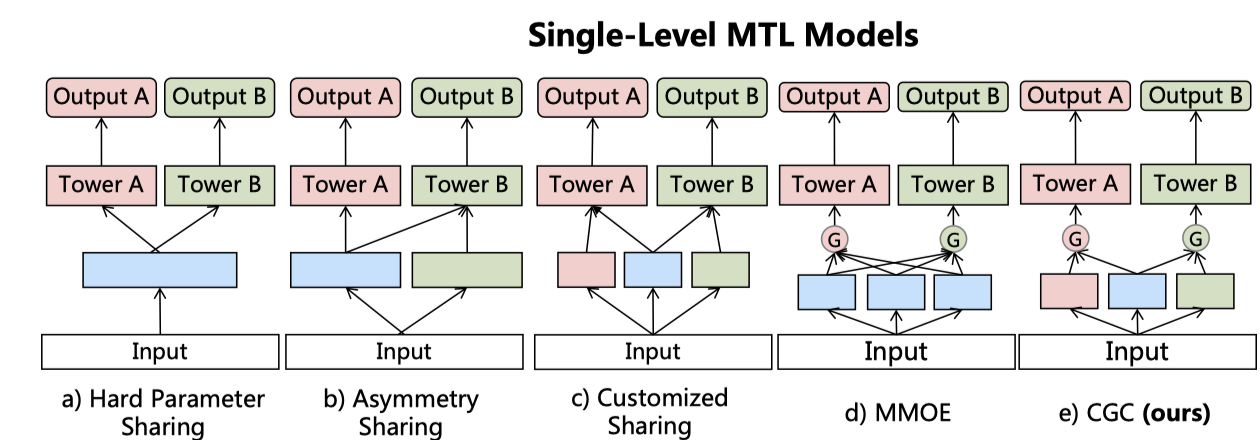
蓝色表示共享层,绿色和粉色表示任务特定层。硬共享被用的比较多,底层参数共享,顶层不同任务使用多塔结构,但这种结构容易导致负迁移。后面的非对称共享、自选共享是文中尝试的两种结构。MMoE中全部专家被所有任务共享,文中的改进也是主要针对这一点:
- Customized Gate Control:改进其实就是显示区分了任务特有的专家和共享专家,按文中解释,尽管MMOE算更为通用的结构,但它也很难收敛到CGC。不加区分地共享全部专家,很可能难以学到任务之间的关联并且带来噪声。至于门的结构,和上面MMOE一致,只不过对于某个任务,门的输入为对应任务的专家及共享专家。
- Progressive Layered Extraction:主要是将上面的CGC扩展到多层,每层会有共享的专家将下一层全部专家的输出作为输入,因此PLE中不同的任务的参数在上层才会逐步分离(Progressive)。
损失优化:
多任务损失就是每个任务的损失的加权,文中对每个任务的损失做了调整:
$\delta_k^i$取值为${0,1}$,表示第$i$个样本是否属于第$k$个任务。文中做视频推荐,不同任务的样本空间不同: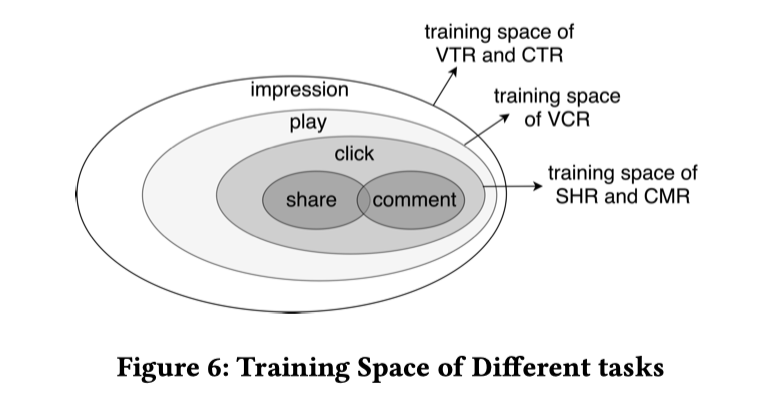
最后的一个实验效果,比较两个任务(VCR(View Completion Ratio),完播率,回归任务;VTR(View Through Rate),有效播放率,二分类任务)的效果: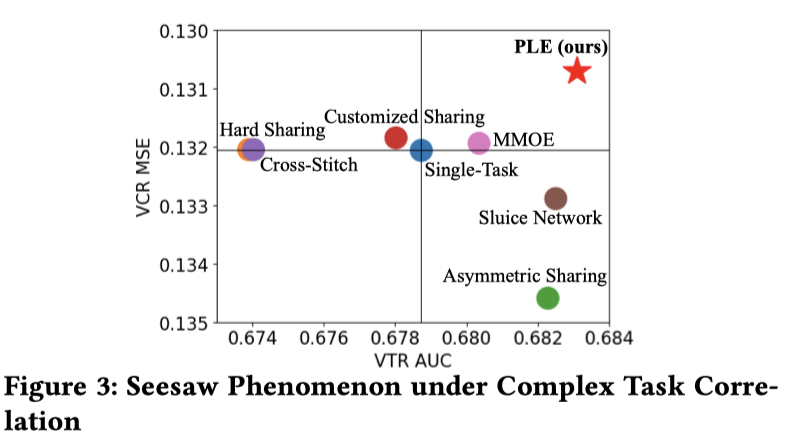
MMOE实现了在两个任务上都不比单任务差,PLE提升更多一些,其他都出现了负迁移或者跷跷板现象。
2018 SIGIR ESMM
Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate 全量空间多任务模型:一种估算点击后转化率的有效方法
ESMM是一个针对电商领域的多目标优化模型,它同时将pCVR、pCTR和pCTCVR融合进一个统一的模型,因此此模型可以一次性得出三个优化目标值(即可以同时优化三个目标,值得注意的是原论文里它只优化了pCTR和pCTCVR,主任务CVR体现在CTCVR这一项中,这避免了部分用户没有点击导致无法计算CVR的问题,是非常优秀的转换)。同时,ESMM这一多目标优化模型同时解决了“训练空间和预测空间不一致的问题”及“同时利用点击和转化数据进行全局优化”这两个关键问题。前者即SSB(Sample Selection Bias)问题(利用两个完全隔离的神经网络,模拟了“曝光到点击”和“点击到转化”两个阶段,样本是是在全量空间进行的选择),后者可看做购买转化数据稀疏问题(Data sparsity)的解决方案(共享Embedding层)。该模型属于典型的shared-bottom结构,形式为SIMO(Single Input Multi out),输入是user和所有曝光的物品(这里应该还有有随机采样的简单负样本),输出包括物品是否点击,物品是否被点击并转化。
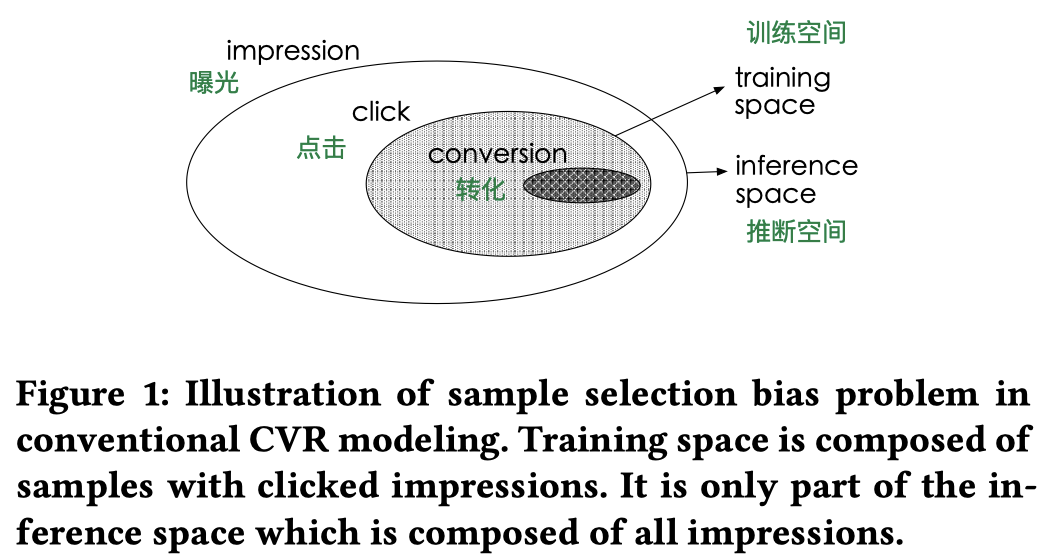
CVR模型训练空间与预测空间不一致问题:由于购买行为是在第二步产生的,因此在训练CVR模型时,直观的做法是采用点击数据+转化数据(上图灰色和深灰色区域数据)训练CVR模型。在使用CVR模型时,因为用户登录后直接看到的不是具体商品详情页(用户点击后才会展示的页面),而是首页或者列表页,因此CVR模型需要在产品曝光的场景(上图中最外层圈内数据)下进行预估。这就导致了训练场景与预估场景不一致的问题。模型在不同场景下肯定会产生有偏的预估结果,进而导致应用效果的损失。
当然可以换个思路解决问题,即针对第一步的场景,构建CTR预估模型;再针对第二步场景,构建CVR预估模型,针对不同的应用场景应用不同的预估模型,这也是电商或广告公司常采用的做法。但这个方案不好之处在于CTR模型与最终优化目标脱节,因为整个问题最终的优化目标是“购买转化”而非“点击”,在第一步仅考虑点击数据,显然不是全局最优化转化率方案。
为了达到同时优化CTR和CVR模型的目的,阿里巴巴提出了多目标优化模型ESMM(Entire Space Multi-task Model)。ESMM可以被当做一个同时模拟“曝光到点击”和“点击到转化”两个阶段的模型。
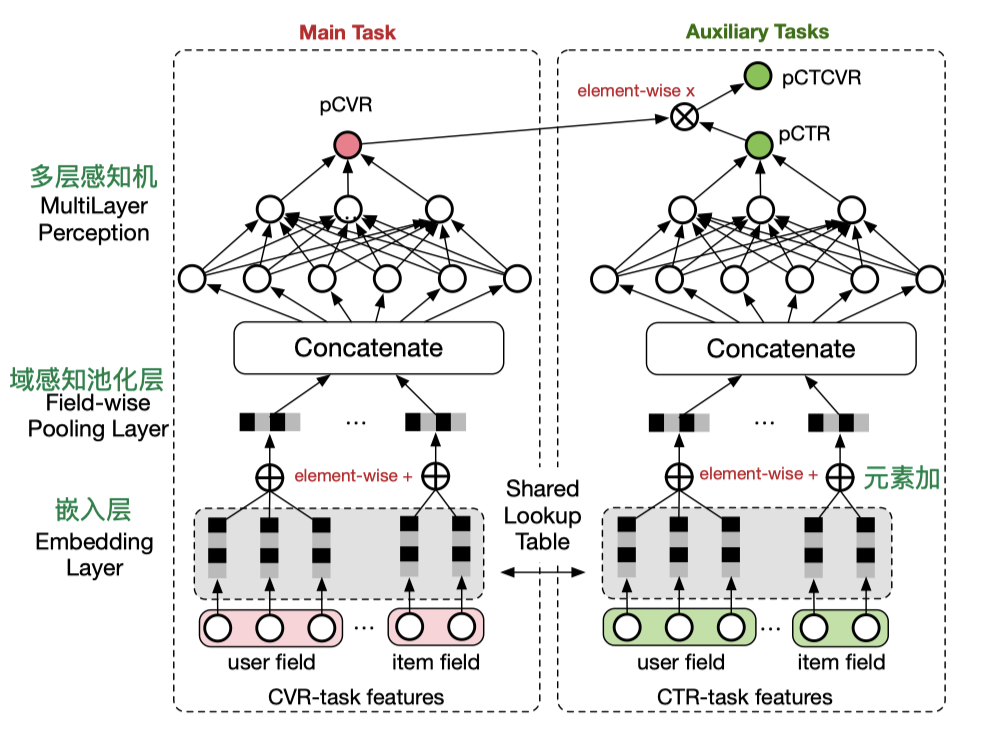
从模型结构上看,底层的Embedding层是CVR部分和CTR部分共享的,共享的Embedding层的目的主要是解决CVR任务正样本稀疏(购买转化的物品很少)的问题,利用CTR的数据(正样本很多)生成更准确的用户和物品的特征表达。
中间层是CVR部分和CTR部分各自利用完全隔离的神经网络拟合自己的优化目标pCVR(post-click CVR,点击后转化率)和pCTR(post-view Click-through Rate,曝光后点击率)。最终,将pCVR和pCTR相乘得到pCTCVR。
pCVR、pCTR和pCTCVR的关系如下:
pCTCVR是指曝光后点击转化序列的概率。
损失函数:包括了两个任务的损失项,即CTR和CTCVR,根据所有曝光样本的计算所得,没有CVR任务的损失,如下:
其中,是CTR和CVR网络的参数,$l(\cdot)$是交叉熵损失,上式右半部分,将分解为两部分$y$和$y\&z$,实际上,它利用了点击和转化的顺序依赖性。
特征表示迁移:嵌入层将大规模的稀疏输入映射到低维嵌入中。它提供了深度网络的大多数参数,而学习这些参数(嵌入层参数更新)需要大量的训练样本。在ESMM中,CVR网络的嵌入层与CTR网络的嵌入层共享。它遵循迁移学习的范例,因为对CTR任务的进行训练的样本是所有曝光的样本,比CVR任务的样本要丰富得多。这种参数共享机制使ESMM中的CVR网络能够从未点击的曝光样本中学习,主要解决了CVR任务中的数据稀疏性。
参考
知乎余文毅:当我们在谈论Multi-Task Learning(多任务/多目标学习)
知乎yymWater:详解谷歌之多任务学习模型MMoE(KDD 2018)
Multitask Learning: A Knowledge-Based Source of Inductive Bias
Multitask Learning of Deep Neural Networks for Low-Resource Speech Recognition
Low Resource Dependency Parsing: Cross-lingual Parameter Sharing in a Neural Network Parser
Trace Norm Regularised Deep Multi-Task Learnin
MoE:Adaptive mixtures of local experts
MMoE: Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts
ESSM: Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate