2020年10月,在CCF大赛主页看到了风电机组异常数据识别与清洗的比赛,提供了12台风机的一年的SCADA(数据采集与监视控制系统)真实运行数据,因为收集的数据来自实际运行的风机,存在大量异常点,举办方希望参赛者根据提供的数据集建立无监督聚类模型,识别出SCADA数据中的异常数据。我们比赛中最好成绩排名为第6名,后来有好多大神找到了更多的异常点,排名直线上升。我们A榜最终成绩排名为15/1122,B榜最终成绩排名为18/1122。
CCF大赛官网:https://www.datafountain.cn/competitions
比赛链接:https://www.datafountain.cn/competitions/451
赛题任务
依据提供的12台风力电机1年的10min间隔SCADA运行数据,包括时间戳信息、风速信息、风机转速信息和功率信息等,利用机器学习相关技术,建立鲁棒的风电机组异常数据检测模型,用于识别并剔除潜在的异常数据,提高数据质量。此任务未给出异常数据标签,可看做聚类任务,为引导选手向赛题需求对接,现简单阐述异常数据定义。异常数据是由风机运行过程与设计运行工况出现较大偏离时产生,如风速仪测风异常导致采集的功率散点明显偏离设计风功率。
数据说明
- 数据文件依次为:
| 文件类别 | 文件名 | 文件内容 |
|---|---|---|
| 数据集 | dataset.csv | 12台风机运行数据文件,无标签 |
| 提交样例 | submission.csv | 仅有三个字段WindNumber\Time\label |
- 数据集中各个字段说明如下:
| 字段英文名 | 字段中文名 |
|---|---|
| Time | 时间戳 |
| WindSpeed | 风速 |
| Power | 功率 |
| RotorSpeed | 风轮转速 |
| WindNumber | 风机编号 |
- 风机参数说明如下:
| 风机编号 | 风轮直径 | 额定功率 | 切入风速 | 切出风速 | 风轮转速范围 |
|---|---|---|---|---|---|
| (m) | (kW) | (m/s) | (m/s) | (r/min) | |
| 1# | 99 | 2000 | 3 | 25 | 8.33-16.8 |
| 2# | 99 | 2000 | 3 | 25 | 8.33-16.8 |
| 3# | 99 | 2000 | 3 | 25 | 8.33-16.8 |
| 4# | 99 | 2000 | 3 | 25 | 8.33-16.8 |
| 5# | 100.5 | 2000 | 3 | 22 | 5.5-19 |
| 6# | 99 | 2000 | 3 | 25 | 8.33-16.8 |
| 7# | 99 | 2000 | 3 | 25 | 8.33-16.8 |
| 8# | 99 | 2000 | 3 | 25 | 8.33-16.8 |
| 9# | 99 | 2000 | 3 | 25 | 8.33-16.8 |
| 10# | 99 | 2000 | 3 | 25 | 8.33-16.8 |
| 11# | 115 | 2000 | 2.5 | 19 | 5-14 |
| 12# | 104.8 | 2000 | 3 | 22 | 5.5-17 |
- 另外,评测标准是12台风机的平均F1值。
数据分析
首先,解决这个赛题的方法是无监督学习方法。不是简单的二分类问题,因为没有标签。如果通过半监督的方式进行人为打标,会由于数据量大、费事费力、标注不一定准确,而导致风险过大,造成过拟合。然后,我们发现12台风机的特征中【时间戳,风速,风轮转速,功率】,时间戳是以10分钟为间隔进行采集的,这是一致的。因此,在后续主要分析了风速与功率、风轮转速与功率的关系,即三个特征【风速,风轮转速,功率】。接下来,我们分别计算了12台风机中三个特征的协方差系数,发现风速和风轮转速的相似程度很高,因此,在后续的聚类方法中,更多的是只考虑风速和功率之间的散点图关系,来评估每种方法检测出的异常点是否合理。
单个特征的可视化
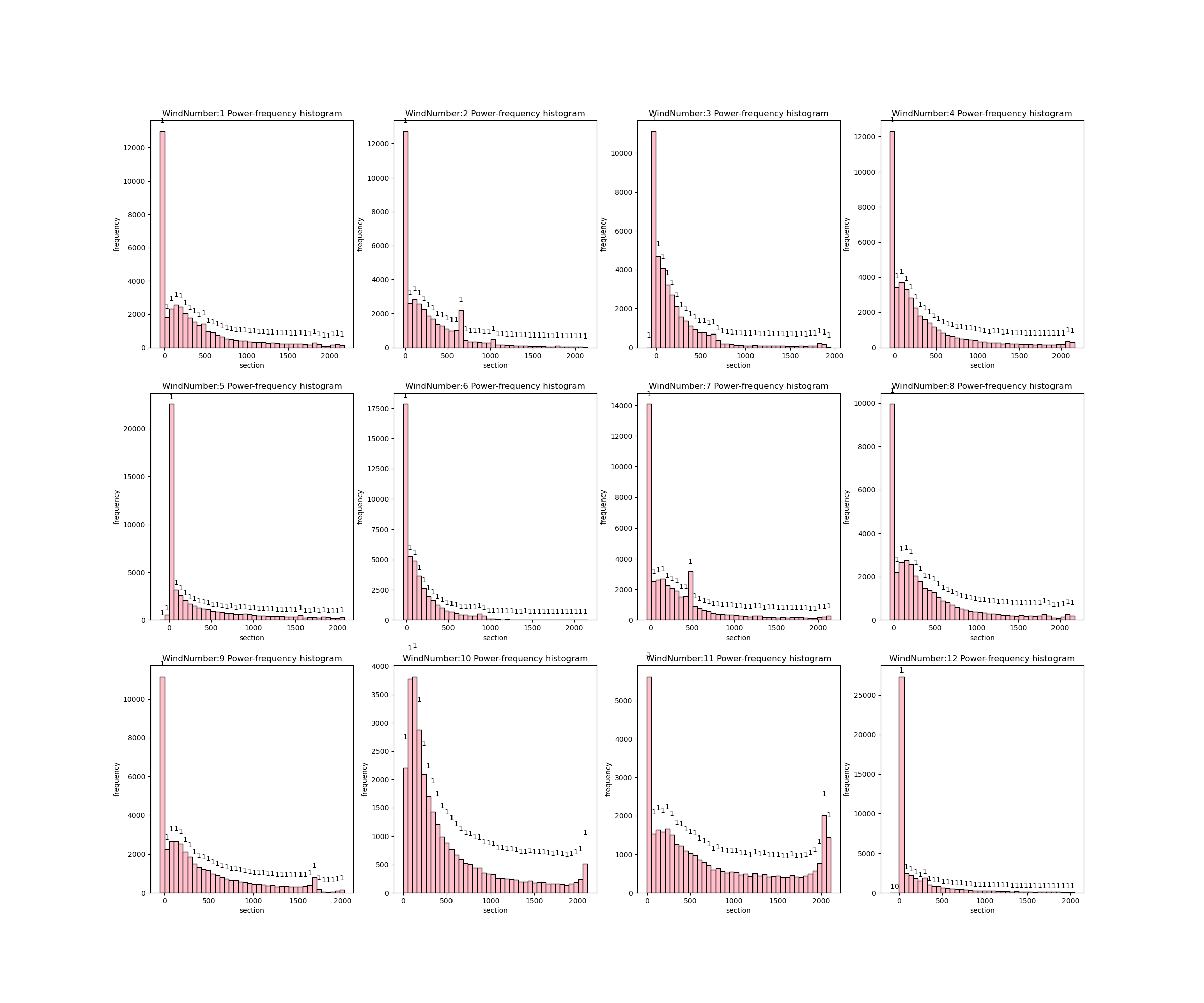
- 12台风机的功率密度直方图:可以看出每台风机功率的分布并不是呈现正态分布,12台风机功率在0值附近概率分布较大。
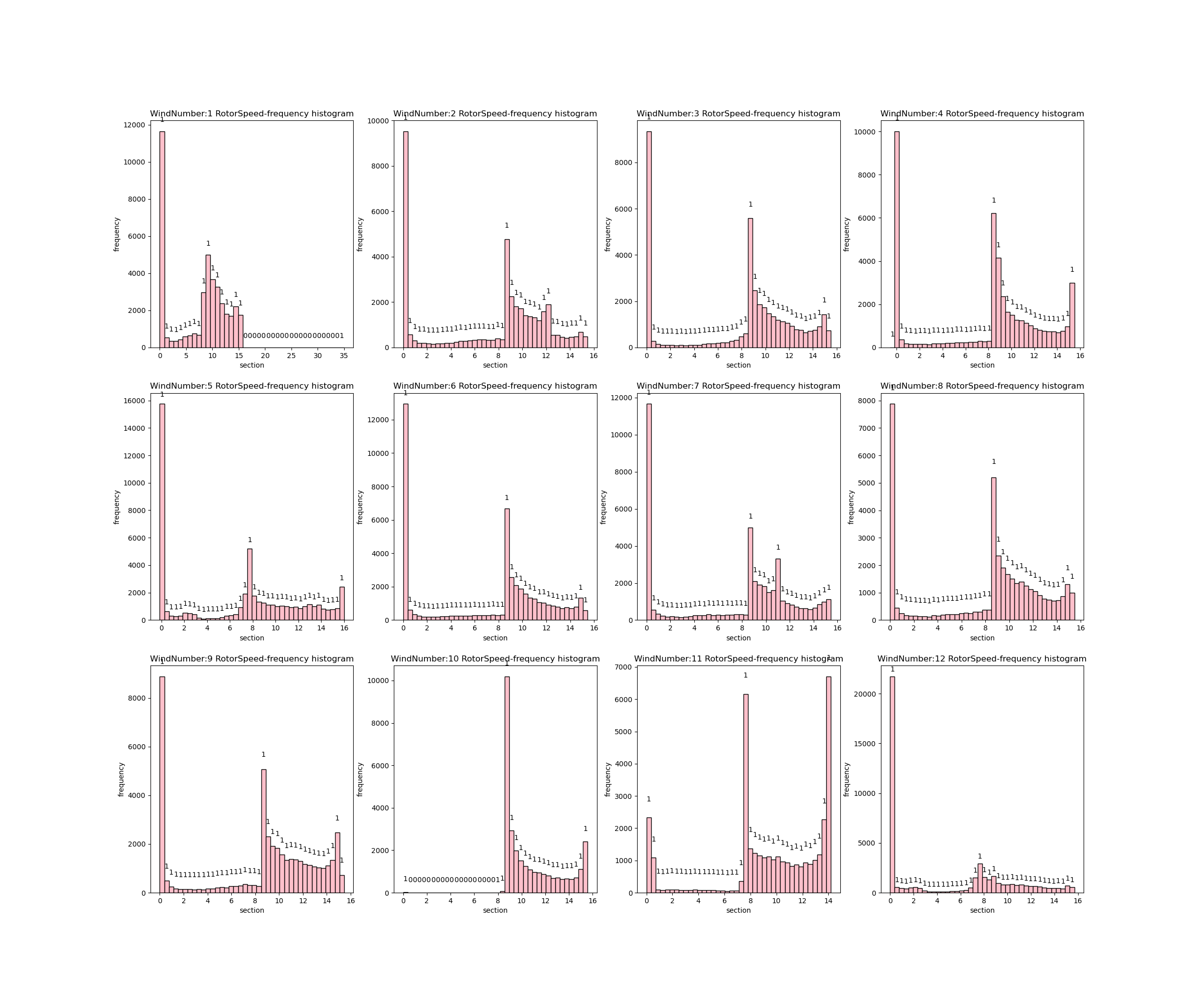
- 12台风轮转速密度直方图:从图中可以看出除了10号风机,其他的风轮转速为0的概率密度较高,12号风轮更为异常。因此,可以分析分析出风轮转速应主要集中于8-15之间,在此范围外的风机转速出现异常数据可能性较大。
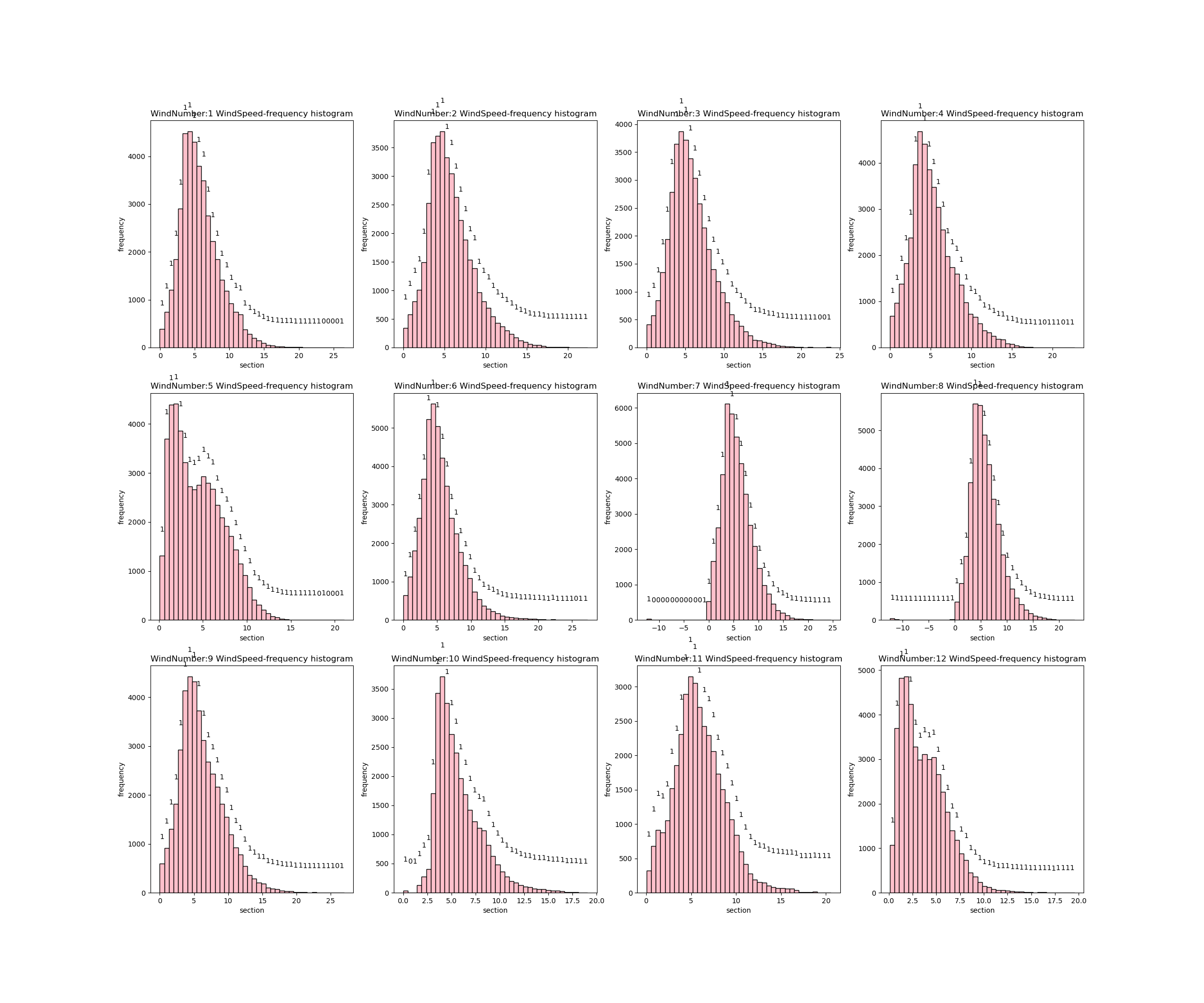
- 风速密度直方图:可以看出大部分风机的样本风速呈现正态分布,其中6号风机和12号风机呈现正偏态。
方法
我们的方法主要包括三种,分别是:基于规则的方法、四分位法和基于密度聚类的方法。
基于规则的方法
这里主要根据数据说明中的风机参数来进行判定,起初我们严格按照每天风机对应的参数来检测出每台风机的异常点(第一步检测),后来,看群里讨论,说给定的风轮转速偏高,于是我们进行逐步检测,比如同一类型的一致,不同类型的分别测,最终找的较为理想的是风轮转速全部定为5r/min为最好(这里我们不一定测得是最优值)。故基于规则的方法将判断出3类异常点:
- 小于0的风速、小于0的风机功率以及风轮转速小于5的记录标记为异常点。
- 低于对应风机的切入风速,且风机功率大于0的记录标记为异常点。
- 所有风速大于12.5m/s且功率在1500kW以下的记录标记为异常点。
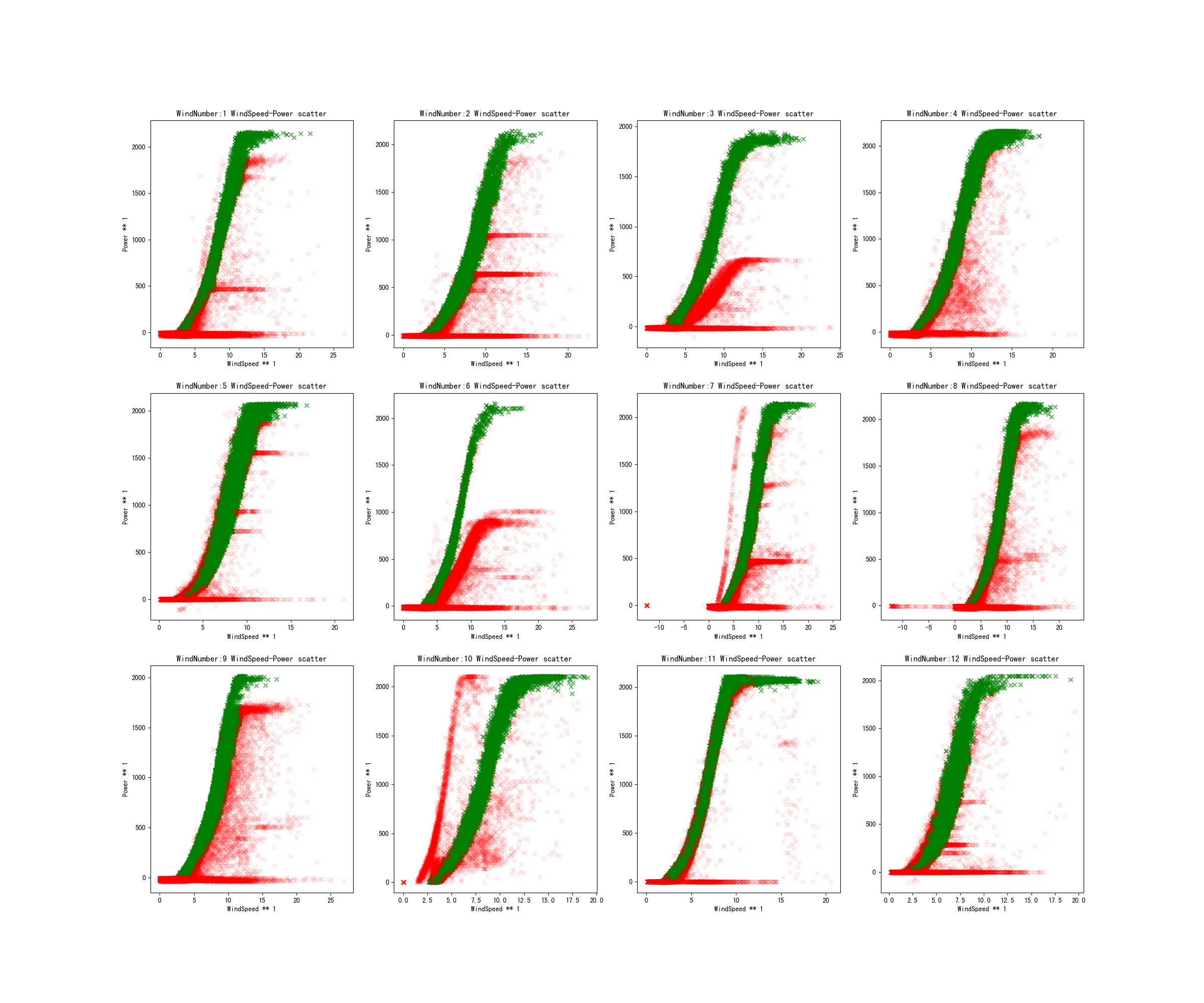
此时,可以看一下风速-功率曲线图(红色点为当前步骤筛选出的异常点):
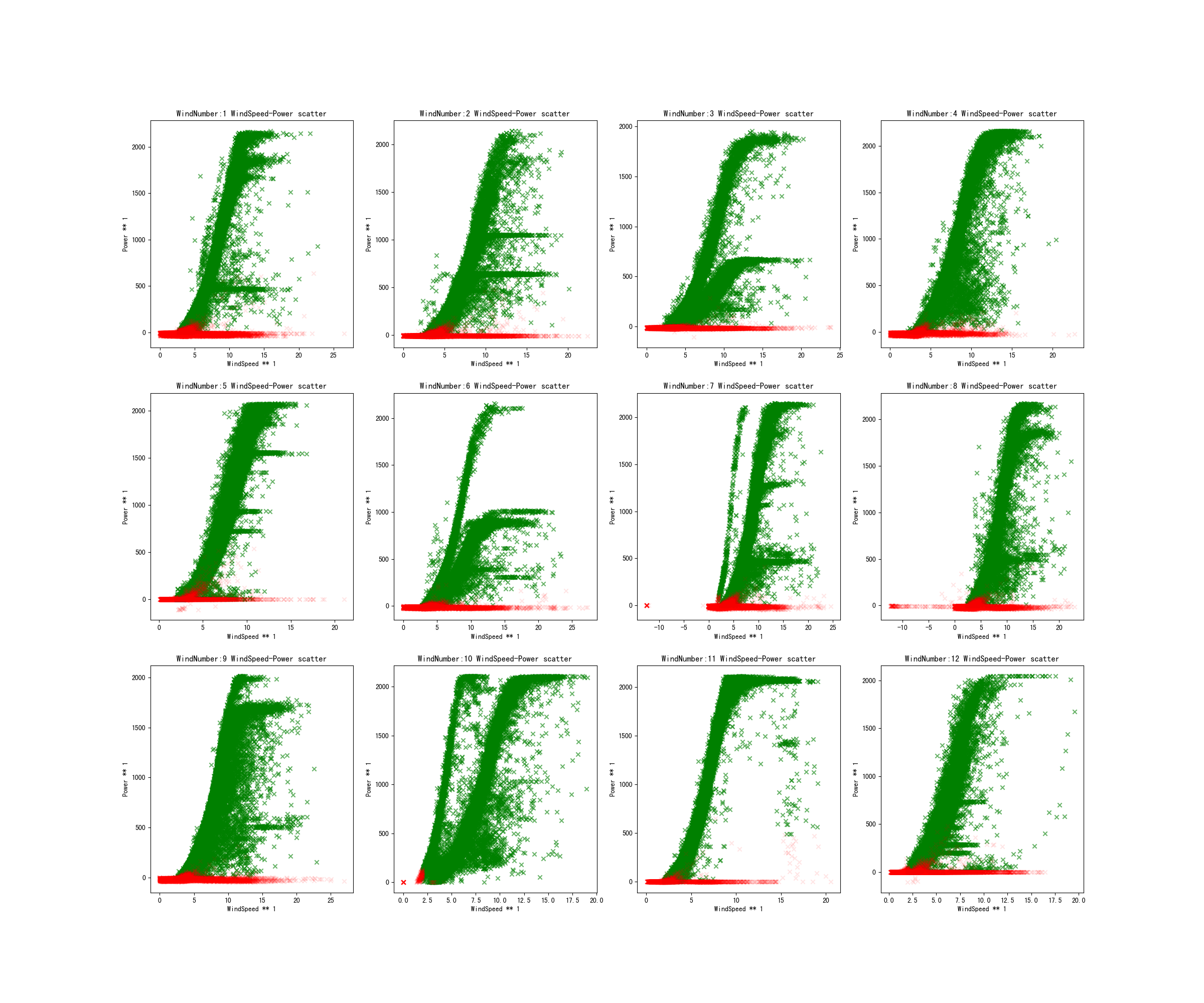 上述可以发现部分风机都有多条风速-功率曲线,但只有一条是正常值,比如3号和4号风机,矮的肯定是异常点,接下来讲述如何去掉唉矮的这条曲线。
上述可以发现部分风机都有多条风速-功率曲线,但只有一条是正常值,比如3号和4号风机,矮的肯定是异常点,接下来讲述如何去掉唉矮的这条曲线。
准备工作,这里要用到风轮转速立方-功率曲线,利用下文提到的四分位法,不过不是按25%和75%划分,而是0%到90%来还划分,风轮转速立方的间隔取100,每个风机的风轮转速立方范围不一致,所以有哦不同的总间隔数。这里去掉这些散点,是为了便于下一步的保留一条曲线。
1
2# except_one_step()每个风机分开执行
result = except_one_step(dataset=dataset_pr,model=QuartileModel(by=('RotorSpeedCube', 100), low_percent=0, high_percent=90), del_col='WindSpeed')去除其他风轮转速立方-功率异常曲线,只保留一条。具体操作是异常曲线的点密度低于正常曲线(比较细长),对于风机功率,我们取100为间隔,对于风轮转速立方,我们取50为间隔,统计个每个区间内点的个数。小于10的异常的区间,大于50的我们将其作为正常值,也可看做有效最高峰。
1
result = except_one_step(dataset=dataset_pr,model=SplitHistogram(bin_col='Power', bin_range=50, by=('RotorSpeedCube', 50)), del_col='WindSpeed')
但是上述两步会存在误标点,即把正常的点标记为异常的点,比如风机5和风机11有很多误标点。因此这两步检测出的异常点为记录下来,后续会利用恢复模型来将其纠正为正常点。利用风轮转速处理后,得到的风速-风机功率曲线图如下:
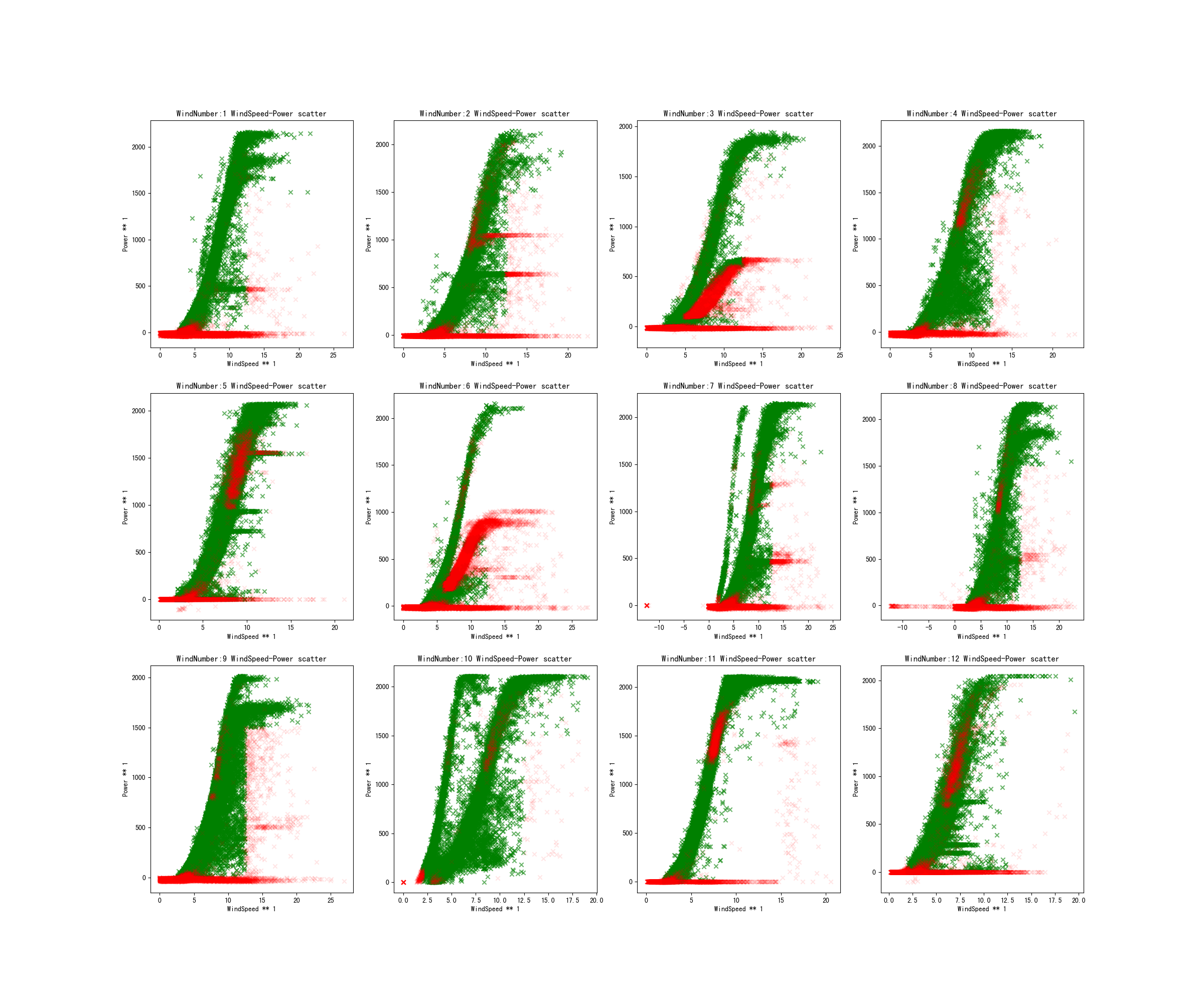
四分位法(Quartile Method)
四分位数法是找到将有序数据集划分为四个相等部分的三个数值,每个部分包含数据集中总观测值的25%。举个例子来说,一个风机数据集包含个功率观测值,那么如何利用四分位法检测异常值呢?
计算第二个分位数,即找到中位数:
计算第一个和第三个分位数:
如果,可利用第一步的将分为两部分,利用1种的公式找到俩部分的二分位数记为和。
如果,则:
如果,则:
正常数据和异常数据判断。得到了和,我们可以计算出四分位间距(Interquartile Range,IQR):
则的正常数据范围为:
其中为下界,为上界。
一般来说,真实场景下风机采集的数据风速-风机功率的曲线图如下所示,可以看出以不同轴划分区间,和之间包含的点基本上都是正常点。下图可以看到只有一条明显的风速-功率曲线,所以我们才要在第一步利用规则的方法去掉风机参数外的异常点和低功率曲线异常点:
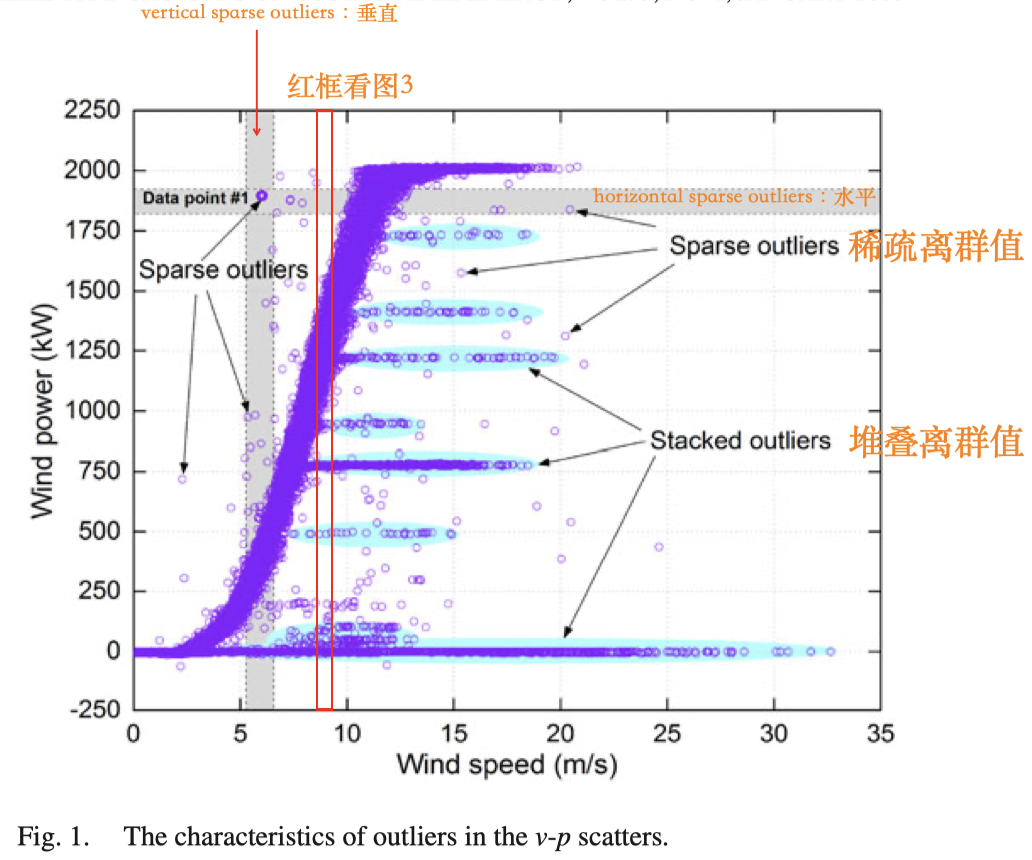
利用四分位法,我们去除了稀疏离群点,包括水平稀疏离群值和垂直稀疏离群点。其中,我们取风机功率的间隔为25,去除了水平稀疏离群点;取风速的间隔为0.5,去除了垂直稀疏离群点,这里离群点即异常点。
1 | result = except_one_step(dataset=dataset,model=QuartileModel(by=('Power', 25), low_percent=25, high_percent=75),del_col='RotorSpeed') |
结果如下图:
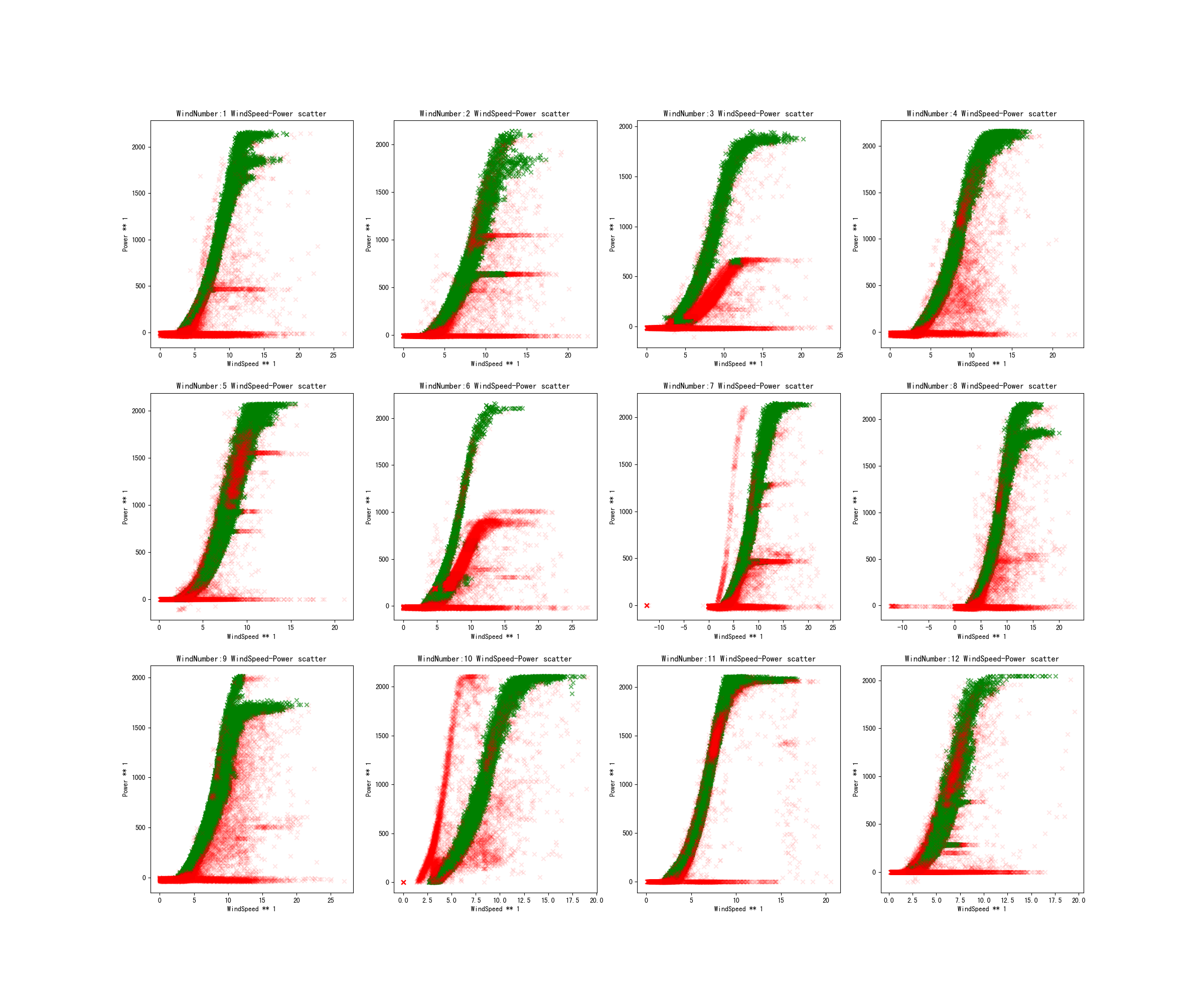 下面介绍的是如何利用基于密度聚类的方法检测异常点。
下面介绍的是如何利用基于密度聚类的方法检测异常点。
基于密度聚类的方法
聚类是无监督学习的重要方法,常见的有哦K-means聚类和分层聚类等,它们把一些对象划分为不同的簇,使得同一个簇内的对象都具有相似的特征,不同簇内的对象则表现出很大的差异。对于不同的风机,由异常点组成的异常簇数量未知且不相同。因此,像K-means这类方法并不适用,因此这里采用了DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法),它的核心思想是:对于一个簇中的每一个点,该点给定半径范围内至少包含最小数量的点,这个数量记为MinPts。这里先标准化
同样,对于包含个功率观测值,DBSCAN的部分定义如下:
- 记为点的邻域,其中距离函数选用欧式距离;
- 如果,且的邻域对应的至少包含MinPts的点,则称点是点密度直达的点,是一个核心点;(不具有对称性)
- 同样,若从点到点是密度可达的,到中间有一连串密度可达的点,即,那么到也是密度可达的。(不具有对称性)
- 对于和,如果存在核心点,使均由密度可达,则称和密度相连。(具有对称性)
- 对于邻域和MinPts,一个簇是满足如下条件的的非空子集:
- 对于,且由密度可达,那么;
- 对于,和密度相连。
- 异常点(噪声)是不属于任何簇的点。
DBSCAN的处理步骤如下:
- 设定,MinPts都设定为7,选的是调参得到的最优值,这里要提前将风速和功率最大最小归一化。
- 任意选择一个点,将它标记为已访问,计算出在和MinPts设定下满足密度连接的点,如果是一个核心点,找它的邻域,生成一个新的仅包含的簇;否则标记为异常点。
- 遍历邻域的每一个点,如果它不属于任何簇,把它加入到簇;如果它是一个核心点,把的邻域合并到
- 重复步骤3,直到不能找到核心点,然后返回步骤2。
结果如下:
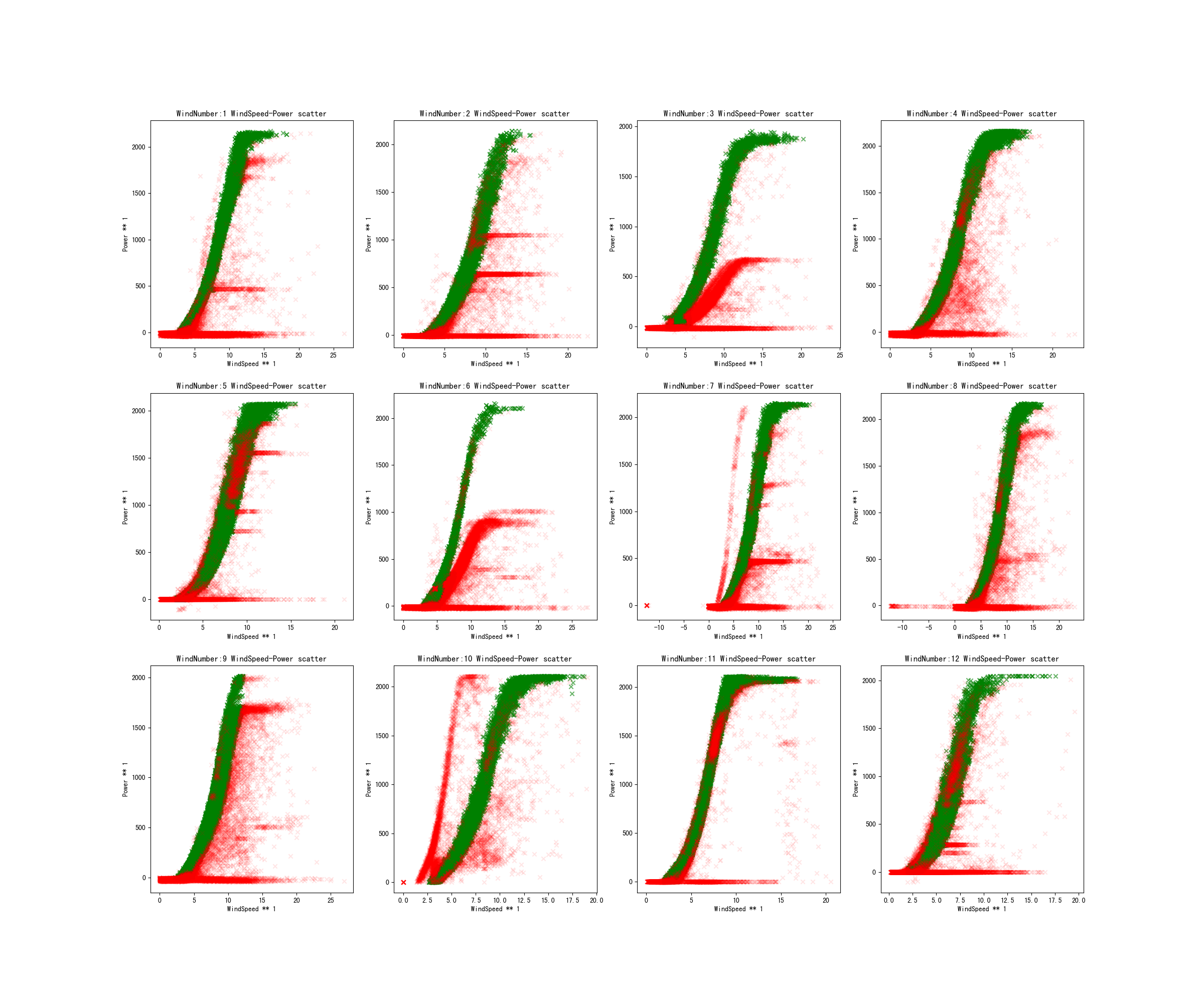
误标点恢复主要是判断正产点的左右边界,将边界内的误标点都恢复成正常点即可,最终恢复如下: