这次调研主要是对强化学习在自然灾害和智慧城市中的应用,共包含四篇论文:
- Firm-level behavior control after large-scale urban flooding using multi-agent deep reinforcement learning(GeoSim’19, Chicago, IL, USA)洪灾后企业交易链恢复问题。
- Coordinating Disaster Emergency Response with Heuristic Reinforcement Learning 飓风引发洪灾的救援调度问题。
- Multi-agent reinforcement learning for adaptive demand response in smart cities (Journal of Physics CISBAT 2019)建筑物群控温节省电费问题。
- A Deep Reinforcement Learning-Enabled Dynamic Redeployment System for Mobile Ambulances(2019 UbiComp)救护车护送患者后重新部署问题。
下面按照应用场景,数据,方法和评估来介绍上述文章。
论文一:企业交易链恢复

这篇文章利用多智能体深度强化学习技术,在洪灾后指导公司采取行为,加快恢复到灾前状态。文章得出的结论是灾后公司应首先采取稳定供应商和开展恢复工作,然后寻找客户和拓展业务。
应用场景
文章选取东京荒川盆地,由于该盆地靠近东京城市的中心部分,许多公司都坐落于此。另外,荒川河流流经该盆地,若这条河泛滥,很可能造成巨大的破坏,预计许多企业将被迫长时间停工,并且被淹没的地区要花费一段时间才能完成排水。因此,随着时间的推迟,洪水泛滥造成的损失可能会越来越多。
数据
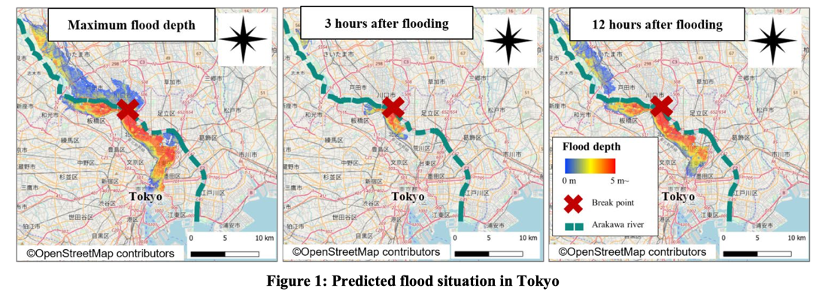
- 洪水模拟分析的数据:数据来自国土交通省旅游局(MLIT)荒川下游河道所提供的荒川河流地区洪水模拟结果,洪水模拟场景需要用该数据与MLIT创建的假定洪水淹没区域图绘制手册一起进行。这个数据集包含335个场景,每个场景具有不同的防洪堤破坏位置(个人理解:选取不同的场景,具有不同的防洪堤破坏位置,意味产生随机的初始状态)。这些数据是100 m-mesh图像,包含了如破坏位置和淹没深度的时间序列数据(防洪堤破坏后一个月的时间序列数据,间隔为10分钟)(These data represent 100 m-mesh figures containing information such as breakdown location and time-series (10 minutes time series data for one month after the levee breakdown) data of inundation depth.)。文中采用了由Ikeuchi等人提出的高破坏情景(a scenario with high damage identified)。下图显示了最大淹没深度以及灾难发生后3小时和12小时的淹没深度。洪水从断裂点开始逐渐扩散,在东京市中心的广阔区域内深度最大超过5 m。
- 供应链网络数据:数据集来自信用报告机构Teikoku Databank Ltd.(TDB),该数据集涵盖了2015年近165万家公司总部和580,000家分支机构的信息,在日本所有47个县和地区中,占日本187万家企业的近90%,其中包括162万家注册公司和24万家其他公司(2016年经济普查)。包括公司的代码,地址,行业类型和销售额。此外,根据TDB交易数据,2016年有近500万笔企业间交易观测数据。这些数据包括总部之间的交易信息,例如供应商和客户的公司代码,交易项目和估计的交易金额。该公司的代码使网络分析可以与该公司及其分支机构的数据相关联。将该数据的交易量与基于I/O表的区域间交易进行比较,可以得出$R = 0.9$的高相关性,这表明这些数据的交易量足以全面掌握生产活动。
方法
仿真环境设计
首先,将位于灾区荒川盆地的大约30,000家公司和170,000个商业伙伴作为agents。Agents之间可以作为业务合作伙伴相互联系。假设一步是一天,则模拟时间是灾难发生后2个月(60步)。模拟的目标是直到整个供应链的交易额恢复到灾难发生前水平的80%。 洪水泛滥地区的每个公司都会根据淹没深度遭受不同程度的洪水破坏,并失去客户和生产能力。模型通过使用深度强化学习通过反复试验,在灾难发生后的这三个时期内(前、中、后期)自主确定对公司行为的最佳控制。
Agents可以采取5种actions:
- 采取恢复行动,可以缩短恢复时间;
- 与以前的业务合作伙伴重新签约;
- 探索新的业务合作伙伴,可以选择供应商或者客户;
- 业务扩展。如果公司有签约客户,则可以增加其中的交易额;
- 不采取行动。
另外,假设agent的行为会影响其他agents,当他们成为业务合作伙伴时,他们在订单接收和下达之间就具有关系,这会影响生产活动。
假设一个公司的生产力$Y$在恢复过程中,遵循Cobb-Douglas函数:
论文中假定比例因子$A$是固定的,$L$为劳动力,$\alpha$为劳动份额 ,$K$为资本,$\beta$为资本份额。假定正常产值为$y$,通过下式来计算洪灾影响的受灾公司的减少产量$\Delta y$:
$\Delta l$为人工减少率,可以看做员工死亡率;$\Delta e$为资本减少率 ,可以看做电气设备损坏与道路淹没情况的乘积。
深度强化学习
定义在时间时,agent观测的到的状态是,采取的动作是,它可以获得一个奖励为,并过渡到一个新的状态,论文用的是Q-Learning算法,它学习一个动作-价值函数的方法,决定在当前状态下一步应采取哪个动作,可以通过Q-Learning来更新:
其中$\alpha(0 \leq \alpha \leq 1)$是学习率,$\gamma (0< \gamma <1)$是一个折扣率。作者采用多层神经网络进行深度强化学习,输入的状态包括影响公司行为控制的因素,例如灾难和交易环境以及整个供应链的交易状态。
多智能体深度强化学习
增强智能体间学习(RIAL,Reinforcement inter-agent learning),如下图所示:
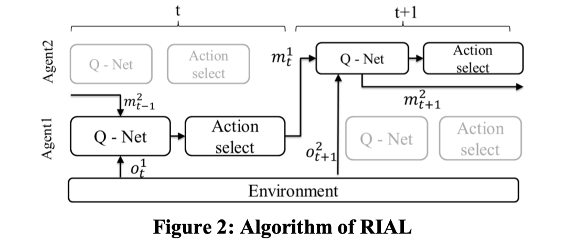
在时间$t$时,agent 1使用Q-net(一种学习函数),同时使用环境的观测值和agent 2之间的交互作为学习数据。 之后,agent 2会以相同的方式学习。这样在学习过程中就可以将agents之间的相互作用考虑在内,不仅使公司的利润最大化,而且使所有代理商的利益最大化,这是一种多智能强化学习的合作关系设定。
实验评估
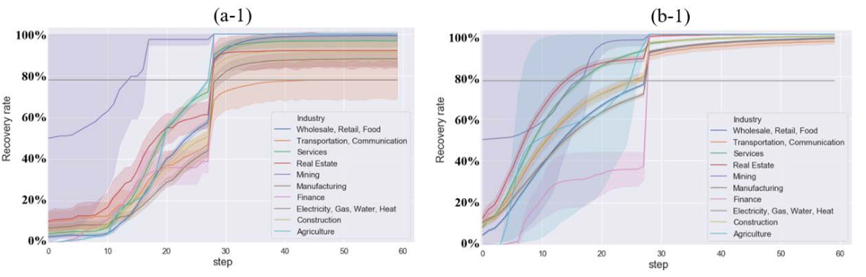
(a-1)采取随机action方法:前面一定时间内行为浪费,第10步才开始逐渐恢复。
(b-1)经过学习:大多数灾后行业从早期就恢复了生产,房地产(Real Estate)和服务业在大约两周内恢复了b-1灾前80%的状态。
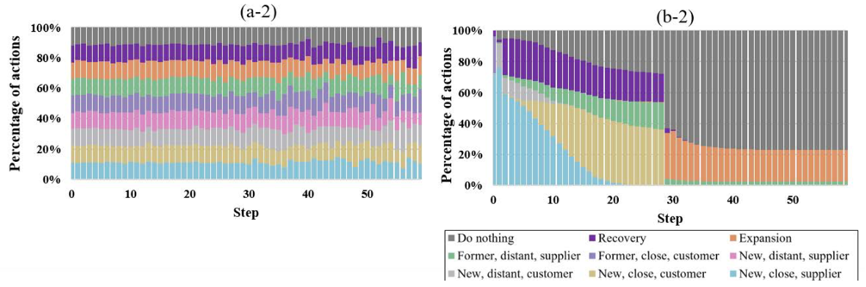
图(a-2),(b-2)显示了行业学习前后行为变化的比较。学习后,每个公司代理商都表现出行为方式的变化。灾后,许多公司已采取了有意义的行动,初期,确保供应商稳定,并恢复工作(恢复行为可以加快恢复);在中期,倾向于有寻找客户,在后期,倾向于扩展业务。
总的来说:这篇文章利用荒川河流提供的洪水模拟场景数据集模拟环境,伴随着环境的变化(洪灾信息、交易环境和供应链交易状态),agents采取相应的actions(5种)。基于此利用RIAL进行学习,并指导公司的行为。
论文二:志愿者调度

这篇文章提出了一种启发式的多智能体强化学习调度算法ResQ,可以在动态环境中,有效地调度志愿营救者去救援受难者。ResQ有两个功能:
- 利用社交网络数据快速识别出志愿者和受难者;
- 在复杂的动态环境中优化志愿者营救策略,ResQ算法通过一个启发式函数加快训练过程,该启发式函数通过识别一组特定于其他行为的行为来减少状态行为空间。
应用场景
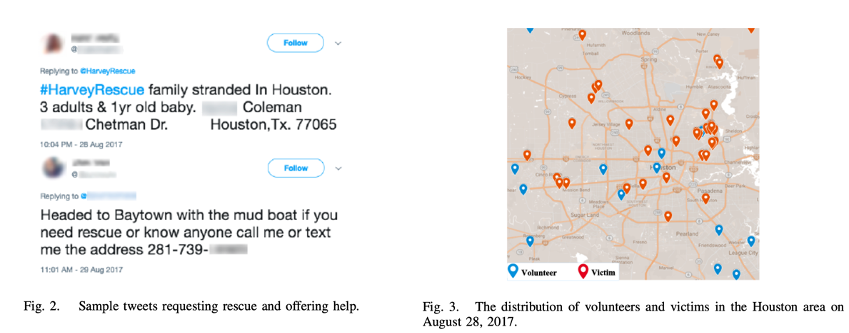
当Harvey飓风于2017年8月25日登陆美国休斯敦部分地区,成千上万的受难人几乎同时打了911服务,由于线路资源有限,因此受难者则转向社交媒体寻求帮助,并用地址发布请求。同时,许多志愿者愿意提供救助服务,故需要协调,若不妥善协调,多名志愿者营救一人,便会造成人力浪费,因此需要为优化资源分配提供指导。下图为推特求救信息和志愿者愿意提供帮助的推文和受灾人员分布。
现实世界中的资源协调问题非常具有挑战性,原因有很多:
- 样本量很小,尤其是在灾难初期,几乎没有可用数据时。任何决策支持系统都需要快速行动并迅速做出决策。
- 需要资源协调的现实环境是一个高度复杂的系统,具有多个不确定性。例如,志愿者和受难者的位置在动态变化,任意受难者的救援时间根据交通,道路封闭和紧急医疗等因素而变化,其中许多因素也在动态变化。
- 没有为灾害的调度问题建模的明确定义的目标函数,尤其是当受难者需要紧急护理或协作救援工作时。
数据
利用Twitter API爬取2017年8月23日至2017年9月5日共两周的Twitter数据,并基于SVM训练了3个分类器,第一个分类器区找出与Harvey飓风相关的Twitter,共173315条,第二和第三个分类器与从Harvey飓风相关的Twitter中找出志愿者和受难者的Twitter,共13953条和16535条。
获取地理坐标:如果推文具有GPS坐标,直接把GPS坐标当做地理坐标;如果没有,根据会结合其他信息来源来推断其位置,例如个人资料填写的位置,或者分析推文内容,借助世界地名词典数据库,找到位置名称和地理坐标。上图是选择休斯敦市一块边长为50英里的正方形区域,划分为个网格,将志愿者和受难者的地理位置坐标映射到正方形区域。

方法
问题定义
定义3.1:时间$t$时志愿者集合为,总的志愿者数为$N$;
定义3.2:时间$t$时受难者集合为,总的受难者数为$M$;
定义3.3:一个营救任务时间cost为,$D$是该营救任务中志愿者和受害者的距离,是营救时间(比如救上船),把受难者送至距离营救地点最近的避难所。这里假设每个营救任务和都一样,只考虑。
定义3.4:营救调度任务,随着时间$t$变化,和在变化,因此在时间$t$时,需要从中找到一个最优的营救调度方案,使得时间$t$时的营救总时间最小,可以被写成一个矩阵。假设这里有个志愿者去营救的受难者,营救调度方案可以被表示为一个矩阵:
其中,$1\le i \le N, 1 \le j \le M$。
营救调度问题被定义如下:
这里不知道作者有没有写错,感觉应该是至少为0,如果志愿者人数大于受难者人数,每个志愿者并不一定都要有营救任务。
ResQ:启发式多智能体强化学习(MARL)
MARL设置:agents是所有的志愿者,agents在这个网格环境里移动去救援受难者,换句话说,这是一个包含$N$个agent的Markov游戏,$N$是agents的数量,$S$是states集合,$A$联合action空间,$P$是转移概率函数,$R$是reward函数,$\gamma$是折扣因子。
Agent:$N_t$是时间$t$时agents数目;
State :为在时间$t$时,可调度的志愿者$i$所在网格位置,此时全局状态为,$S$是一个有限集合。
Action :一个联合action 表示在时间$t$时为所有可调度志愿者的分配策略,是所有可调度志愿者的数量,action空间表示agent $i$下次迭代可采取的移动方向,移动方向可以被表示为4个离散action,即,在时间$t$时,如果给出了一个agent $i$的state 和action ,我们可以计算出在时间时,agent $i$的状态,位于角落agent的action空间较小,policy $\pi$为一个序列actions,为最优policy。
折扣因子$\gamma$:0到1之间,量化即时reward和未来reward重要性差异。
转移函数$P$::状态转移概率表示在当前状态采取联合action 的情况下转移到的概率。
Reward函数$R_i \in R = S \times A \rightarrow(-\infty,+\infty)$:营救调度问题中的reward被定义为当agent在某个state采取action时来自环境的反馈。每个agent的奖励函数为$R_i$,并且同一位置的所有agent具有相同的reward函数。 第$i$个agent尝试最大化自己的期望折扣reward:
具体的reward设置作者没有描述。营救问题的目标是找到使总reward最大的最优策略$\pi^*$(agents的一系列动作)。引入状态值函数$V^{\pi}(s)$来评估不同policy的性能。$V^{\pi}(s)$表示从当前状态$s$采取policy $\pi$得到总折扣reward的期望:
根据贝尔曼优化公式,有:
下面是 ResQ的营救调度算法,作者设计了一个启发式选择action的算法。

实验评估
对于分类器方法:用SVM与LR、KNN、CART做了分类性能比较,训练数据的Tweet标签应该是作者自己打的。
对于强化学习方法:对比的有如下几种,红框内为作者提出的方法:
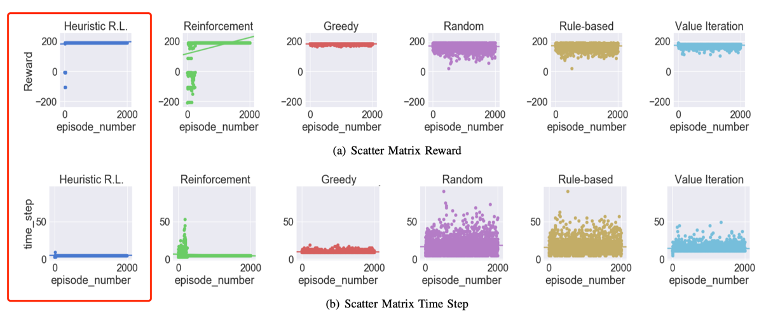
仿真环境:利用OpenAI Gym进行环境仿真,一个episode为志愿者营救完所有的受难者,没有过多的描述。
总体流程:作者先爬取两周的Tweet数据,然后区分每一天的志愿者和受难者,并根据推文获取坐并标映射为网格坐标,最后利用OpenAI Gym自定义仿真环境,基于该环境进行相关实验。
论文三:节能协调控制

这篇文章主发表在CISBAT 2019要为了解决用电高峰时期变得越来越频繁的问题,需求响应是指协调电力负载,使它们对价格信号做出反应并相互协调以减少用电高峰。作者使用多智能体深度确定性策略梯度(multi-agent deep deterministic policy gradient,DDPG),一种model-free的强化学习控制算法,它优于标准的Q-Learning强化学习,具有model-free和易操作的特点,作者在10座带有存储电量设备的建筑物模拟环境中实现了该控制器,并根据电价改变信号做出相应,相互协调来降低电费。控制器将室外温度,充电状态,一天中的时间(hour)和电价作为state。
应用场景
对于夏季(6月至8月)德克萨斯州奥斯汀的10座建筑物的制冷设备,每个建筑物有自己的存储电量设备,如何在花费更少的电力情况下,协调控制所有的建筑物(存电和放电)维持其恒定温度。
数据
这篇文章没有说,另一篇文章介绍这篇文章用到的仿真环境设计:
- 论文题目:CityLearn v1.0: An OpenAI Gym Environment for Demand Response with Deep Reinforcement Learning
- 链接:https://dl.acm.org/doi/pdf/10.1145/3360322.3360998

可以参考到用到的数据,应该是一样的,包括:
- 建筑物时间序列信息:月、小时、该天的类型(8种)、夏令时状态、室内温度[C],平均未满足制冷设定点差异[C]、室内相对湿度[%]、设备电力[kWh]、DHW加热[kWh]、制冷负荷[kWh]。
- 建筑物属性:建筑物类型、气候区、安装太阳板能量(kW)、热力泵信息、电热水器、降温水箱、DHW_Tank。
- 天气数据:室外干球温度[C],室外相对湿度[%],漫射太阳辐射[W / m2],直接太阳辐射[W / m2],6h预测室外干球温度[C],12h预测室外干球温度[C], 24h预测室外干球温度[C],6h预测室外相对湿度[%],12h预测室外相对湿度[%],24h预测室外相对湿度[%],6h预测散射太阳辐射[W / m2],12h预测散射 太阳辐射[W / m2],24h预测漫射太阳辐射[W / m2],6h预测太阳直射辐射[W / m2],12h预测太阳直射辐射[W / m2],24h预测太阳直射辐射[W / m2]。
- 发电功率的历史记录:包括自1月1日00:00以来的小时数和小时数据:交流逆变器功率(W)。
方法
强化学习(RL)可以用马尔可夫决策过程(MDP)形式化。MDP包含:一组states $S$,一组actions $A$,reward函数$R:A \times A$和状态之间的转移概率$P:S \times A \times S \in [0,1]$。策略$\pi$表示states与actions之间的映射$\pi : S \rightarrow A$,value函数$V(s)$是在状态$s$中开始并遵循策略$\pi$时agent的预期reward,即:
其中$R_{ss’}^a$可以被表示为$r(s,a)$,即在采取action $a=\pi(s_k)$后,从当前state $s$到下一个state $s’$所获得的reward,$\gamma \in [0,1]$是折扣因子,为1表示未来reward与当前 reward同等重要。当模型 dynamic,即$P,R$未知且必须通过agent与环境的交互进行估算时,RL特别有用有两种方法可用于确定每个状态$V^{\pi}$值:
- 一种model-based的方法,其中首先学习模型的奖励$R$和转移概率$P$,然后通过迭代求解上述方程式方程式来找到值。
- 一种是model-free的方法,agent可以学习与每个$(s,a)$对相关的值,而无需显式计算转换概率或期望reward。
Q-learning由于其简单性而成为最广泛使用的model-free强化学习技术。对于有限状态集的任务,可以用一个表存储不同的state-action values,或者叫做Q-values,Q-values更新如下:
其中$s’$是下一个state,$\alpha \in (0,1)$是学习率,对于$\alpha=0$,没有学习发生,而对于$\alpha=1$,在每次迭代中,先前的Q-value被新的Q-value完全覆盖。
深度确定性策略梯度(Deep deterministic policy gradient)
对于复杂环境中state和action是连续值的情况,表格式的Q-Learning无法应用,其他强化学习算法(例如深度确定性策略梯度(DDPG))更适合这些类型的问题。 DDPG是一种评价(critic)行为的方法,它使用两个DNN来概括state-action空间。actor网络将当前state映射到它认为最佳的action。 然后,critic网络通过将这些action以及state映射到Q值来critic这些action,如下图所示。 Q值表示在特定state下采取action预期reward累计总和。
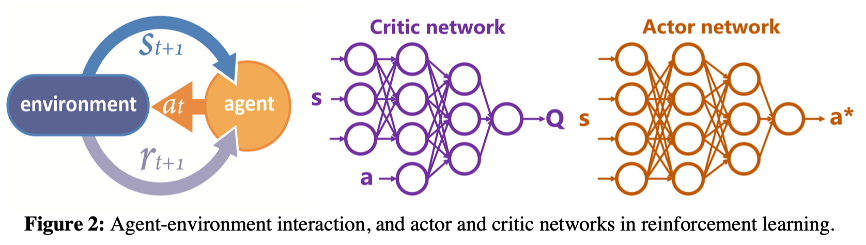
通过拟合从Q-values更新公式,计算的Q值来更新critic网络,其中$\alpha=1$,并最小化Q值及其预测之间的损失,公式(3)。actor网络也被更新,公式(4)。
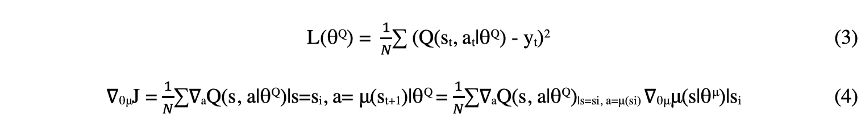
多智能体协调(Multi-agent coordination)
每个建筑物的温度设定点是恒定的,由热泵(heat pump)给提供水箱冷却能量来给建筑物降温,若还不能达到恒定设定温度,热泵会提供额外的冷却能量给水箱,热泵会从电网消耗电力,电价随所有建筑物的总电力需求线性增加。因此,控制器(agent)的目的是通过避免同时消耗过多的电力和消耗较少的能量来降低其电力成本。
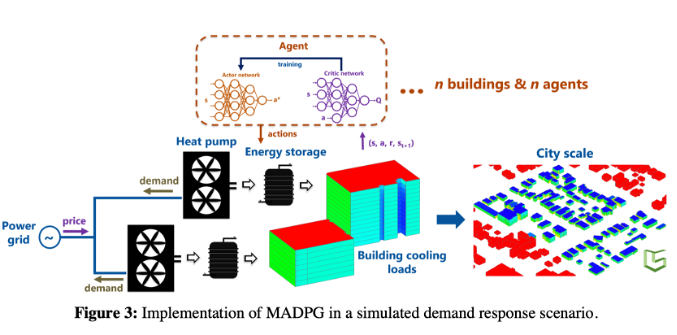
每个建筑物都有其自己的RL-DDPG控制器,并且agent的数量与建筑物的数量(本例中为10个)相同。作者模拟了两个不同的RL控制器:DDPG控制器及其多智能体变体MADPG。在DDPG中,每个代理仅知道其自身的state和action,而在MADPG中,每个agent也都知道其他所有agent的state。State包括一天中所处的小时,室外温度,冷冻水箱的充电状态。action表述为每隔一小时存储或释放一次能量。
作者关注夏季(6月至8月)德克萨斯州奥斯汀的10座建筑物的制冷设备,模拟持续了大约40分钟(CPU:i7-6700 K 4.0 GHz,RAM:64.0 GB)。作者基于OpenAI环境设计了一个CitySim仿真环境,进行自己的实验。
实验评估
这篇文章与三个方法进行了对比,分别是DDPG、基于规则的控制器、基于手工优化的基于规则的控制器。
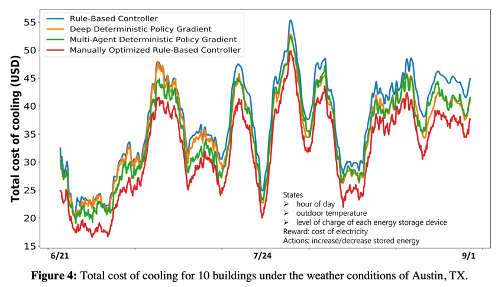
总的来说,这篇文章和相关的另外一篇文章有开源数据和仿真环境设计的开源代码,可以用来参考学习。
论文四:救护车重新部署策略

为了将可用的救护车重新部署到适当的救护站(需要考虑每个救护站的多个动态因素)去更好地接未来的患者,降低救护车接诊患者到医院的时间,文章提出了一种深度得分网络,将每一个救护站的动态因素平衡为一个得分,然后提出了一个深度强化学习框架来学习深度得分网络,基于学习到的深度评分网络,作者提供了一种有效的动态救护车重新部署算法。与基准模型相比,患者平均接诊时间节省约100秒(约20%),并在10分钟内患者的接诊率从0.786提高到0.838。
应用场景
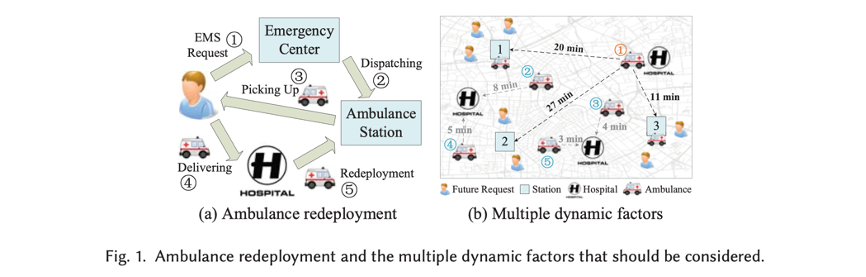
上图(a):(1)患者发出EMS(Emergency Medical Services)请求;(2)急救中心分配救护站;(3)救护站派救护车接患者;(4)接到患者后送至医院;(5)将救护车重新到救护站。
上图(b):假设在1救护站的未来患者有3个,救护车部署到1会迅速将他们接走。目前来说,贪婪地调度算法可以取得很优的性能。
救护站的动态因素:(1)该救护站附近未来的预期患者数量;(2)当前救护站内已有救护车数量(考虑救护站容量);(3)当前新的可用的救护车到达该救护站的时间;(4)其他救护车的状态,比如救护车2和4目的地医院离1号救护站更近,等它们送完患者再去1号救护站比立刻部署1号救护车到1号救护站更好。另外还有救护站覆盖范围等,动态因素比较复杂,难以仅仅通过手工规则来解决。
数据
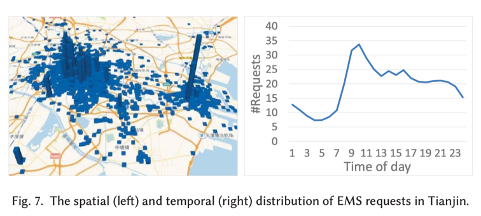
中国天津市的EMS系统收集的数据,该数据由EMS请求记录,道路网络,救护站和医院组成,如下所示:
EMS请求记录:EME请求记录包含来自患者的120呼叫。每条记录都包含一个时间戳,一个经纬度。从2014年10月1日到11月21日,收集了51天的EMS请求记录数据,其中包含23,549条记录。平均而言,每天约有462个EMS请求到达,每小时有约20个EMS请求。EMS请求的时空分布如图7所示。可以看出,EMS请求在空间和时间上是不平衡的。
救护站:天津有34个(地理位置由经度和纬度组成)的救护站。
医院:天津有41家医院,救护车可以将病人运送到这些医院。
道路网:该路网包含天津的道路信息,包括路顶点的经纬度,路段的长度和限速信息等。总共有99,007条路顶点和133,726条路段。在仿真环境中,作者使用道路网定义任意两个位置的实际行驶时间。
作者的仿真环境是建立在先前别人仿真环境的基础上(对于地图,一般网格化),比如下面(这篇论文仿真参考的引用论文),更多的仿真设置并没有介绍。使用前31天EMS请求作为训练数据,通过深度强化学习算法来学习深度得分网络。后20天用作测试数据,以基于学习的深度得分网络评估重新部署算法。
方法
深度得分网络(Deep Score Network)
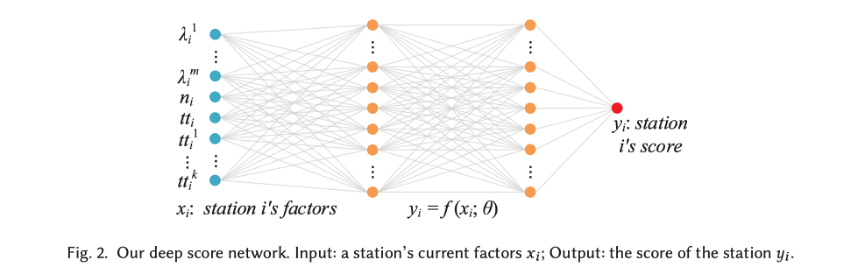
深度得分网络如上图2所示,公式表示为:
包含一个输入层、两个隐藏层和一个输出层,$x_i$是每个救护站的动态因素,$\theta$是所有的参数,隐层都设为20,使用tanh激活函数,输出$y_i$为每个救护站的得分。
其中$(\lambda_i^1,…,\lambda_i^m),n_i,tt_i,(tt_i^1,…,tt_i^k)$为应用场景里介绍的救护站的4种动态因素。
强化学习深度得分网络(Reinforcement Learning Deep Score Network)
因为给定动态因素$x_i$,无法获取标签$y_i$,故不能用监督学习算法。
强化学习框架
可以将动态的救护车调度问题建模为强化学任务:
Station:当一个救护车可用时,假设时间为$t$,可以获取当前的state $s_t$,由所有的救护站的动态因素组成,如下:
其中$I$为救护站的总数。
Action:救护车的部署到那个救护站,$a_t=i$意味着当前可用救护车被部署到救护站$i$,如下:
Transition:state转换时间间隔不定,只有要有新的救护车可用,自动转到下一个state。
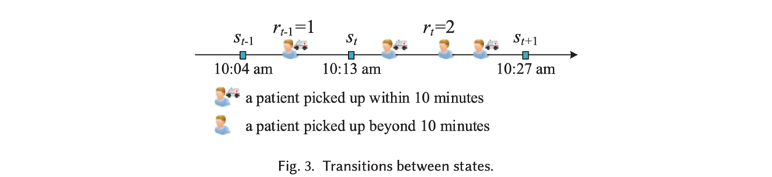
Reward:为,接诊患者的时间小于10分钟的数量。比如有一个患者的接诊时间小于10分钟,因此;有两个患者的接诊时间小于10,因此;
Policy:作者利用策略网络实现策略,是一个概率函数。具体来说,给定当前状态,将每个救护站的动态因素 输入到深度得分网络,等得到输出,组成的嵌入输入到策略网络,它只包含一组参数,即不同的救护站共享一组参数。这是因为作者为所有救护站学习一个得分网络,而不是为每个站点学习一个得分网络。得到所有的,经过softmax函数输出部署到每个站点的概率。
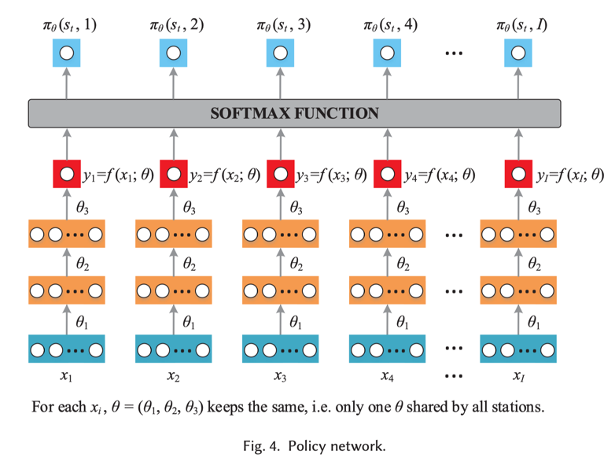
用策略梯度学习参数$\theta$(Learning $\theta$ with Policy Gradient)
目标:学习一个最优策略网络,使得在给定任何state 的情况下,通过遵循策略,agent都能最大化长期折扣reward的期望,即在给定的时间阈值内,接诊患者人数最多。目标函数形式化定义为:
其中,是遵循策略并从state 开始,获得的长期折扣reward的期望;表示从任意随机状态开始,state 从策略采样而得,表述为:
其中是未来reward的折扣率(例如)。也称为state value。另外对于任何state 和action ,可以遵循表示的策略,计算长期折扣reward的期望:
其中,称为state-action value,和关系如下式和下图:

梯度:$J(\theta)$ 对$\theta$的梯度和梯度更新(最大化目标)为:
$\alpha$为0.005。
挑战:由于EMS环境的复杂性,无法获得上述期望,因此采用蒙特卡洛方法随机采样来解决。
动态重新部署算法(Dynamic Redeployment Algorithm
算法1 是用强化学习学习深度得分网络的参数$\theta$。

算法2 是部署,计算每一个救护站的得分,选择得分最大的救护站。

实验评估
选择了6个baseline,RS(随机选择一个救护站)、NS(最近的救护站)、ERTM、MEXCLP和DMEXCLP,有两个评估指标。其余包括其他的分析:解释部署方法的有效性、分析模型部署后推断很快、训练收敛性能分析、用深度得分网络的必要性、考虑救护站所有动态因素的必要性、讨论一些参数的影响(救护站附近的请求个数和救护车数量)、患者数量的影响、方法的鲁棒性等等。
总结
四篇文章总结如下:
| 背景 | 数据 | 方法 | 仿真 |
|---|---|---|---|
| 日本荒川河流,公司交易链恢复 | 洪水模拟数据(来自政府),真实的公司信息数据 | 多智能体深度强化学习 | 利用政府提供的工具和手册仿真 |
| 美国Harvey飓风,志愿者调度问题 | 爬取Tweet数据,设计分类器,识别出志愿者和受难者,确定地理位置信息 | 启发式多智能体强化学习ResQ | 基于OpenAI Gym自定义 |
| 对夏季10座建筑物的制冷设备协同调节 | 夏季(6月至8月)德克萨斯州奥斯汀的10座建筑物的制冷设备信息,天气等信息 | 多智能体变体MADPG | 基于OpenAI Gym自定义,数据和代码开源 |
| 天津市救护车重新部署 | 救护站、医院、道路网和EMS请求数据 | 利用深度强化学习框架来学习深度得分网络,根据得分进行部署 | 未说明 |