这次调研主要参考了2017年的一篇综述《Network Community Detection: A Review and Visual Survey》,文中主要介绍了基于统计推断和机器学习的社区检测方法,还包括一些公开数据集和评估指标等,这里只介绍一些传统方法,更多可以看原论文和参考中第二个链接。

社区结构是复杂网络中广泛研究的结构特征,网络中的社区是节点的密集组合,它们在组内彼此紧密耦合,而与网络中其余的顶点松散耦合。社区检测在理解复杂网络的功能方面起着关键作用。文章将社区发现算法分为四类:传统方法、基于模块度的方法、重叠社区检测方法和动态社区检测方法。
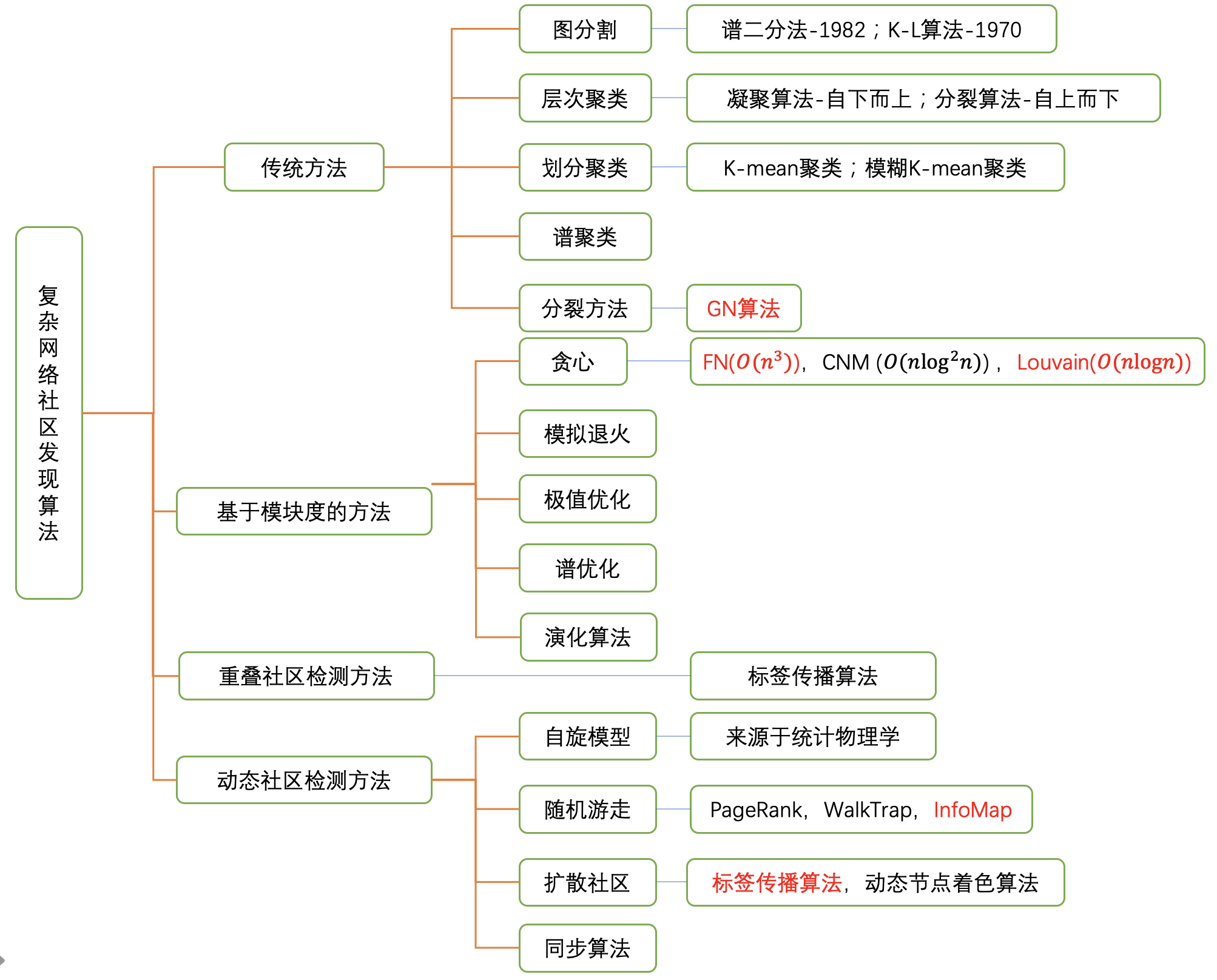
这里首先介绍一下模块度的概念,然后五种算法,分别是传统方法中GN算法,基于模块度方法中的FN和Louvai算法,标签传播算法,以及InfoMap算法。
模块度概念(Modularity)
- Network Community Detection: A Review and Visual Survey
模块度可以用来衡量网络中社区的划分是否优良,它的物理含义是社区内节点的连边数与网络随机情况下社区内的边数之差,占网络总边数的比例,即网络中社区内部实际边的比例减去社区内部期望边的比例。一个好的划分结果其表现形式是:在社区内部的节点相似度较高,而在社区外部节点的相似度较低)。关于模块度的定义,文中列举了模块度定义的更新迭代:
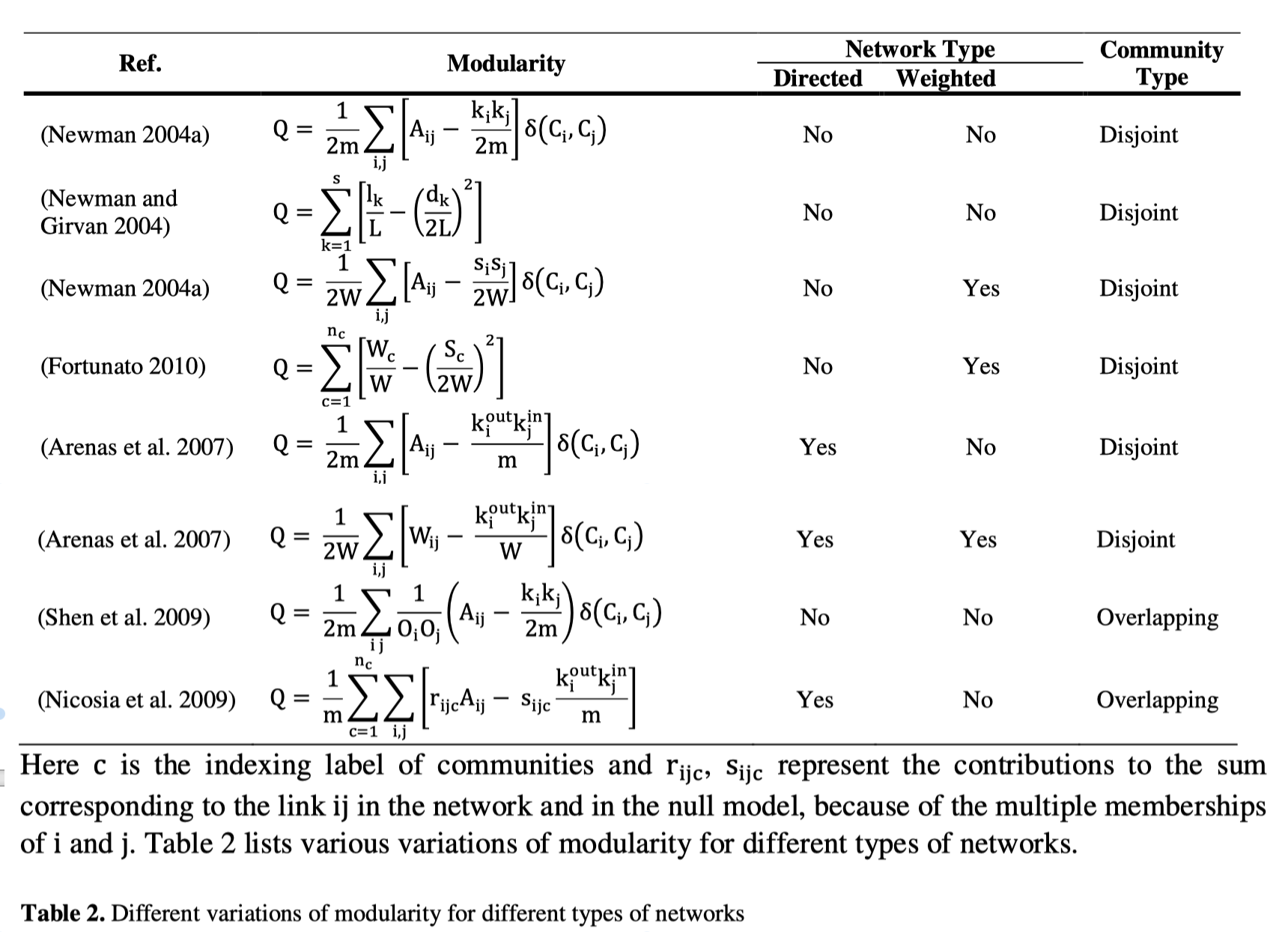
下面是一种最常用的模块度定义公式:
其中,表示节点与节点$j$之间边的权重,网络不是带权图时,表示连边数;表示所有与节点$i$相连的边的权重之和(度数);表示节点$i$所属的社区;表示所有边的权重之和(边数),这里重复计算了边数,所以会除以2。$Q$的取值范围是。
- 当图中只有两个节点,把两个节点各分为1个社区,那么$Q$取值为$-\frac{1}{2}$;
- $Q$的上限为1,越接近这个值,就说明社区结构越明显;
- 在实际网络中,$Q$值常位于0.3和0.7之间。
公式中,节点$j$连接到任意一个节点的概率是,现在节点$i$的度数为,因此随机情况下节点$i$与$j$连边的为权重为$A_{ij}$,接下来将该公式进行如下简化:
其中$\frac{\sum{in}}{2m}$表示社区内实际边的比例,$\left(\frac{
\sum{tot}}{2m}\right)^2$表示随机情况下,社区内期望边的比例。
分裂方法
GN算法-2002
- Community structure in social and biological networks
Girvan-Newman算法(2002)是一种基于介数的社区发现算法,同时,他们二人还提出用边介数来标记每条边对网络连通性的影响。GN算法基本思想是根据边介数(edge betweenness)从大到小的顺序不断的将边从网络中移除直到整个网络分解为各个社区。每条边的边介数可以理解为网络中通过这条边的最短路径数目。GN算法的基本流程如下:
- 计算网络中所有边的边介数;
- 找到边介数最高的边并将它从网络中移除,若不唯一,则随机选一条断开或同时断开;
- 重新计算网络中各条边的边介数,重复步骤2,直到每个节点成为一个独立的社区为止,即网络中没有边存在。
可以根据想要划分的社区个数进行划分,或者根据$Q$值进行划分。
基于模块度的方法
基于模块度的社区发现算法,都是以最大模块度$Q$为目标进行的。快速算法FN和快速模块度最大化算法Louvain的原理非常相似,二者都是基于局部模块度最大化来进行的。
快速算法FN-2004
- Fast algorithm for detecting community structure in network
FN核心算法思想(2004):
- 去掉网络中所有的边,网络的每个节点都作为单独的一个社区;
- 网络中的每个连通部分作为一个社区,将还未加入网络的边重新加回网络,每次加入一条边,如果加入网络的边连接了两个不同的社区,则合并两个社区,并计算形成新社区划分的模块度增量,选择使模块度增量最大的两个社区进行合并;
- 如果一直能够找到使得模块度增大的合并,则返回步骤(2)继续迭代,否则转到步骤(4);
- 遍历每种社区划分对应的模块度值,选取模块度最大的社区划分作为网络的最优划分。
快速模块度最大化算法Louvain-2004
- Fast unfolding of communities in large networks
Louvain算法思想(2008),分为两个阶段:
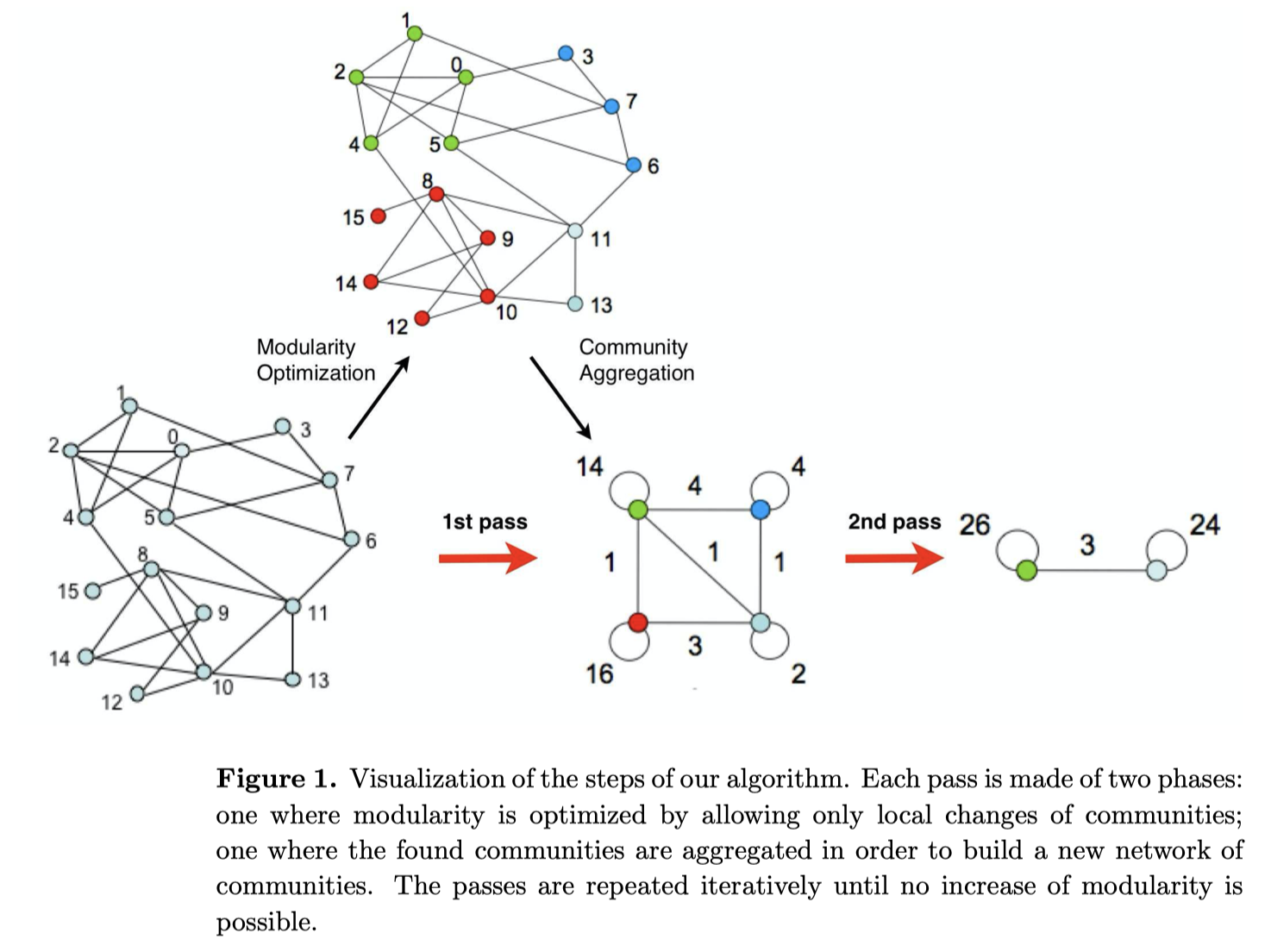
第一个阶段:
- 首先,将网络中每个节点看做一个社区,每个社区内的权重为0;
- 然后,对于每个节点$i$,依次尝试把节点$i$分配到每个邻居节点所在的社区,计算分配前后模块度的变化$\Delta Q$,并记录$\Delta Q$最大的那个邻居节点,如果$\max \Delta Q > 0$,则把节点$i$分配给$\Delta Q$最大的那个邻居节点所在的社区,否则不变;
- 最后,重复2,直到所有节点的所属社区不再变化;
$\Delta Q$公式如下:
其中$k_{i,in}$是社区(比如$c$)内部节点与节点$i$的连边权重之和,这里要乘以2;$\Delta Q$分了两部分,前半部分是把节点$i$加入到社区$c$后的模块度,后半部分是将节点$i$作为一个独立社区时,社区$c$的模块度;在实现$\Delta Q$时可以简化:
第二个阶段:
- 对网络进行压缩,将所有在同一个社区的节点压缩成一个新的节点,社区内节点之间边的权重转化为新节点自连接的权重,社区间边的权重转化为新节点之间边的权重。
- 重复第一个阶段,直到整个网络的模块度不再发生变化。
该方法的论文中提到第一阶段的第2步,遍历节点的顺序对划分社区结果有一定影响,但差距不大,只是会影响算法的时间效率。该方法可以处理无向带权图,官网说可以修改之后应用到有向图。
动态方法
LPA-标签传播算法-2007
- Near linear time algorithm to detect community structures in large-scale networks
Label Propagation(LPA)是一种基于标签传播的局部社区划分算法。对于网络中的每一个节点,在初始阶段,LPA算法对于每一个节点都会初始化一个唯一的一个标签。每一次迭代都会根据与自己相连的节点所属的标签改变自己的标签,更改的原则是选择与其相连的节点中所属标签最多的社区标签为自己的社区标签,这就是标签传播的含义了。随着社区标签不断传播。最终,连接紧密的节点将有共同的标签。
LPA的基本思想是每个节点的标签应该和大多数邻居标签相同(bagging思想),给每个节点添加标签以表示它所属的社区,并通过传播使得社区内部拥有相同的标签。可以看出,LPA与K-means本质很相似。在LPA每轮迭代中,给节点划分社区取决于其邻居中累加权重最大的标签(无权图则每个节点对应标签weight=1),而K-means则是计算每个类中心(社区)到当前节点的距离,并将节点划分到最近的类中。但是二者还是有区别的:
- K-means是基于欧式空间计算节点向量间的距离,而LPA则是根据节点间的”共有关系“以及“共有关系的强弱程度”来度量度量节点间的距离;
- K-means中节点处在欧式空间中,它假设所有节点之间都存在“一定的关系”,不同的距离体现了关系的强弱。但是 LPA 中节点间只有满足“某种共有关系”时,才存在节点间的边,没有共有关系的节点是完全隔断的,计算邻居节点的时候也不会计算整个图结构,而是仅仅计算和该节点有边连接的节点,从这个角度看,LPA 的这个图结构具有更强的社区型;
- LPA无需指定聚类社区的个数,因为它可以看做一个彻底的自下而上方法,而K-means则需要指定聚类的类别个数。
算法描述:
- 先给每个节点分配对应标签,即节点1对应标签1,节点$i$对应标签$i$,也可以用节点id当做初始标签;
- 遍历$N$个节点,找到对应节点邻居,获取此节点邻居标签,找到出现次数最大标签,若出现次数最多标签不止一个,则随机选择一个标签替换成此节点标签;
- 若本轮标签重标记后,节点标签不再变化(或者达到设定的最大迭代次数),则迭代停止,否则重复第2步。
标签传播方式:
同步更新-synchronous
当前迭代中,是基于邻居的上一次迭代中的标签来更新节点的新标签:
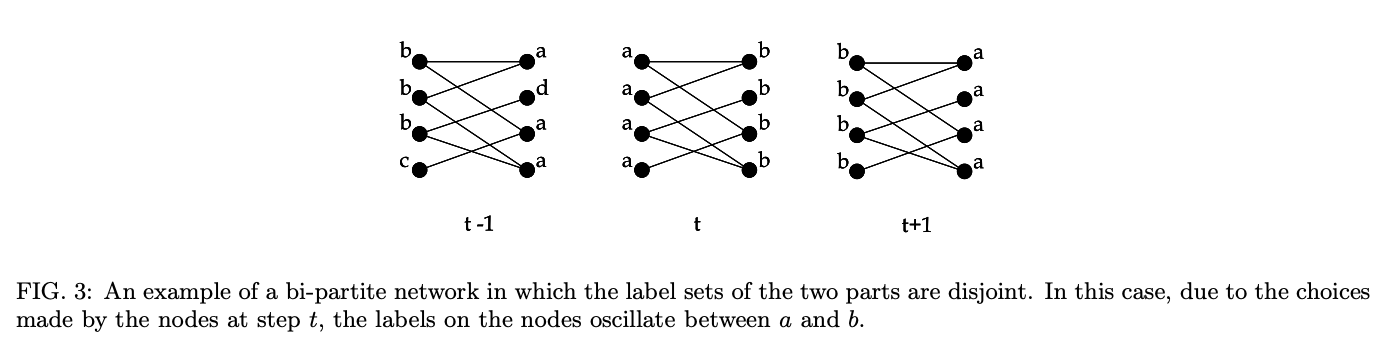
异步更新-asynchronous
节点的标签并不区分当前迭代和上一次迭代,永远都只使用节点最新的标签。 论文中是推荐使用异步更新方式的,主要原因在于同步更新可能出现标签的交替振荡而无法达到稳定态,这种情况很容易在星状图中出现,如下:
如果有先验知识的话,可以给网络中的节点标上先验的标签,然后其他的节点不标标签,这样也可以最后达到社区划分的效果。新浪微博似乎就是走的这个套路,首先会有一些用户打上了标签,然后让这些标签在整个网络中扩散出去,最终的效果就是大部分人都被打上标签。
InfoMap算法-2008
- Maps of random walks on complex networks reveal community structure
- The map equation
InfoMap与压缩编码、层次编码有直接联系,它初始论文题目为Maps of random walks on complex networks reveal community structure,在复杂网络上利用随机游走来揭示社区结构,并利用平均比特增益来决定如何合并社区。
首先需要提一下最小熵原理和最短编码长度,假设一共有$n$个不同的字符,每个字符出现的概率分别是$P=(p_1,p_2,\cdots,p_n)$,那么有两个问题我们可能会感兴趣?
- 如何找到最优编码方案,使得总的平均编码长度最短?(Huffman编码)
- 理论上,这个平均编码长度是多少?(信息熵,如下)
编码的最短平均长度就是信息熵,也即无损压缩能力的极限,通过寻找更佳的方案去逼近这个极限便是最小熵。
对层次编码,考虑需要记忆一个序列:苹果、梨、上海、广州、 深圳、12,45,89。那么,我们一般不会直接按顺序记忆,而是分类记忆:前两个是水果,中间三个是城市,后面三个是数字。我们先对类别进行编码,再对对象进行编码,然后每一类结束加上一个终止标记,如:
| 水果 | 苹果 | 梨 | End | 城市 | 上海 | 广州 | 深圳 | End | 数字 | 12 | 45 | 89 | End |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 000 | 001 | 010 | 000 | 001 | 001 | 010 | 011 | 000 | 010 | 001 | 010 | 011 | 000 |
有了特定层次的编码方案,就可以计算该方案的平均编码长度了,定义:为对象出现的概率,为类别$i$出现的概率,同样也是类别$i$终止标记出现的概率,它们三个都是全局归一化的概率,即:
由于类和类内对象使用两套不同的编码,所以需要分别计算两者的平均编码长度,其中,类的平均编码长度是:
其中,,这是因为类的编码时独立一套的,将类的概率在类间归一化后,代入熵的公式就得到类的理论上的最短平均编码长度了。同样的,对于每个类$i$的类内对象的最短平均编码长度是:
其中,,每个类内对象都用独自的一套编码,这里连同终止标记概率在类内归一化后,代入熵的公式。最后,二者加权平均可以得到总的最短平均编码长度:
这样,对于每一个序列,就需要我们去找到一个层次编码方案,是上式越小越好。
但是,经典的聚类问题并没有这种序列,InfoMap的想法是将聚类的节点网络看做一个有向图,任意两个节点$(\alpha,\beta)$都有一条$\beta \rightarrow \alpha$的边,边的权重为转移概率$p_{\beta} \rightarrow \alpha$。一般来说,节点之间的边也代表着两个点之间的相似度,然后我们可以通过将边的权重归一化来赋予它转移概率的含义。有了这个设定之后,一个很经典的想法——“随机游走”——就出来了:从某个点$j$开始,依概率$p(i|j)$跳转下一个点$i$,然后从$i$点出发,再依转移概率跳转到下一个点,重复这个过程。这样我们就可以得到一个很长的序列。有了序列之后,就能以找到最小的最短平均编码长度为目标来聚类了。
其实,我们不需要进行随机游走模拟,因为事实上我们不需要生成的序列,我们只需要知道随机游走生成的序列里边每个对象的概率,为此,我们只需要去解方程:
或者写成,上式得到的是节点概率最终的平稳分布,但是,单纯的随机游走可能会依赖迭代的初始值,上式的解可能不唯一,比如,有一些孤立的区域,进去便永远出不来了,那么区域外的节点的概率便全为0了。为了解决这个问题,作者引入了”穿越概率“$\tau$:以$1-\tau$的概率按照的概率来随机游走,以$\tau$的概率随机选择网络中任意一个节点跳转,那么,节点$p_{\beta}$的概率为:
相当于把转移概率换成了,$\tau$作为一个超参数,作者取了$\tau=0.15$。
有了,还需要求,即类别的概率,也是终止标记的概率,出现终止标记意味着后面的类是已经不是第$i$类了,所以终止标记的概率实际上就是“从一个类别跳转到另一个类别的概率”,换言之就是随机游走过程中“离开$i$类”这件事情发生的概率,它等于:
若带有穿越概率的话,要将换成,即为:
其中,是类的类内对象数目。现在有了和的形式都出来了,只需要将二者归一化,然后找到最小的总的最短平均编码长度即可。
InfoMap的整个流程如下:
- 定义好节点间的转移概率;
- 数值求解得到$p_\alpha$;
- 搜索聚类方案,使得总的最短平均编码长度尽可能小。
对于第3步,改进版的InfoMap中,算法大致如下:
- 每个节点都初始化一个独立的类;
- 按照随机的顺序遍历每个节点,将每个节点都归到让总的平均编码长度下降幅度最大的那个相邻的类;
- 重复步骤2,每次都用不同的随机顺序,直到不再下降;
- 通过其他一些新的策略来精调前三步得到的聚类结果。
可以发现,InfoMap就是建立在转移概率基础上的一种聚类/社区发现算法,有清晰的信息论解释(最小熵解释),并且几乎没有任何超参(或者说超参就是转移概率的构建)。
参考
Modularity的计算方法——社团检测中模块度计算公式详解
标签传播算法(Label Propagation Algorithm, LPA)初探